
대수적 균등 분할 원리라 하며, 큰 수의 법칙과 밀접한 관련이 있다. 장기간에 걸쳐 확률적 과정의 결과가 어떻게 나타나는지 다룬다.
Convergence of Random Variable
Xi가 iid이며 E(X1)=E(X2)=...=E(Xn)을 만족한다고 가정하자. 이때 ¯Xn=1n(X1+...+Xn)이라고 하자.
그러면 대수의 법칙에 의해서 n→∞, ¯Xn→μ가 된다.
우리는 그러면 ¯Xn을 다음을 만족하는 RV라고 생각해볼 수 있다.

두가지 type(strong, weak)으로 수렴이 인식된다.
Types of Convergence
수렴의 종류는 구체적으로 4가지로 구분된다.
- Almost sure convergence : Yna.s.→Y
- Mean-square convergence : YnL2→Y
- Convergence in Probability : YnP→Y
- Convergence in Distribution : Ynd→Y
위의 관계는 다음과 같은 관계를 가지는 것을 의미하기도 한다.
Asymptotic Equipartition Property, AEP
대수의 법칙 analog 버전이다. 긴 시퀀스 중 매우 작은 부분집합인 'Typical set'의 시퀀스가 주로 나타나는 것을 의미한다.
X1,...,Xn P(X1,...,Xn)인 RV가 iid일 때, n이 충분히 클 경우, 모든 event가 equally surprising함을 의미한다.
수학적으로 n이 크면, −1nlogP(X1,...,Xn)→H(X)이기 때문에 성립한다.
Typical Set
p(x)를 따르는 A(n)ϵ에 대히여 다음의 성질을 만족하는 시퀀스의 집합을 의미한다.
2−n(H(X)+ϵ)≤p(x1,x2,...,xn)≤2−n(H(X)−ϵ)
다음의 Theorem을 만족한다.
Size of Typical Set
Xi가 iid고 p(0)=p, p(1)=1−p이다. 이 때, typical sequence(length n)은 대충 0이 np번 1이 n(1-p)번 발생한다고 생각할 수 있다.
따라서 typical sequence의 수는 (nnp)로 구해보면,
일반적으로 typical set의 크기는 2nH(X)임을 알 수 있다.
Data Compression by AEP
AEP를 사용하면, data를 typical set으로 압축시키는 방법에 대한 경우의 수가 어떻게 될지 알아볼 수 있다.
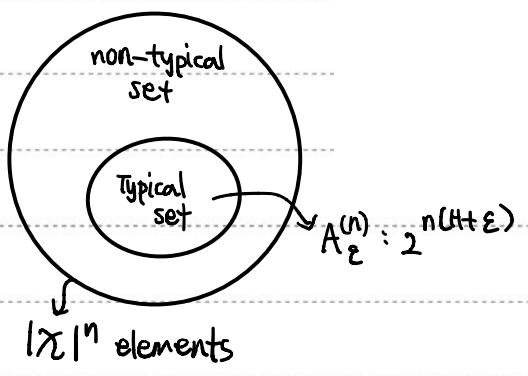
위와 같은 데이터를 저장한다고 생각했을 때, typical set과 non-typical set에 각각 필요한 비트수는 다음처럼 계산할 수 있다.
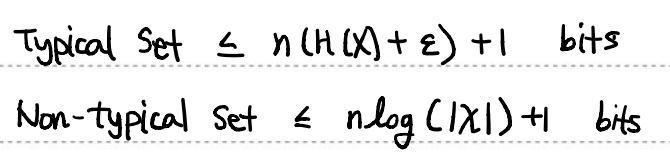
여기에 데이터가 typical인지 아닌지 나타내는 prefix용 1 bit가 추가된 bit수가 필요하다고 생각해보자.
그럼 source code를 압축한다고 생각했을 때,
- Brute force로 non-typical set A(n)cϵ을 찾는다. (크기 ≤|Xn|
- Expected length of codeword(부호어): l(xn)

이렇게 해서 최종적으로 데이터를 AEP에 의해 압축시켰을 경우, 다음을 만족하는 one-to-one source code가 있음을 알 수 있다.
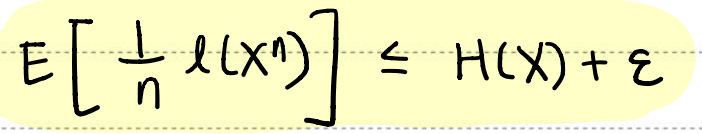
(Xn iid이며 p(x)를 따르고 ϵ>0인 경우)
교과서 내용이 잘 이해가 안가서, 유튜브로 공부한 내용
AEP
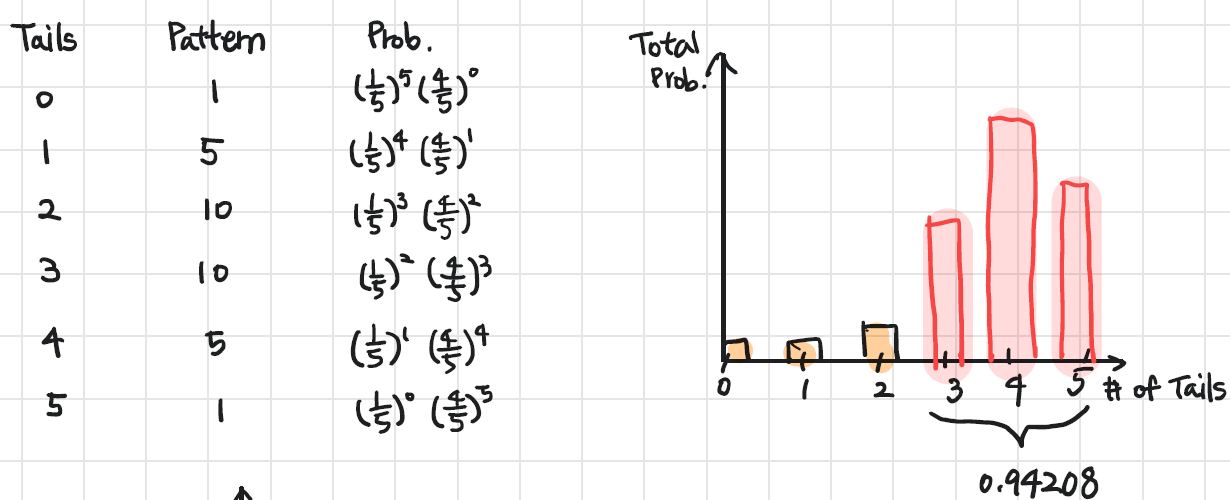
Biased coin을 toss한다고 가정해보자. 확률은 다음과 같다. P(H)=15,P(T)=45
그러면 이제 Toss를 L=5번한다고 생각해보면 확률은 다음과 같다.
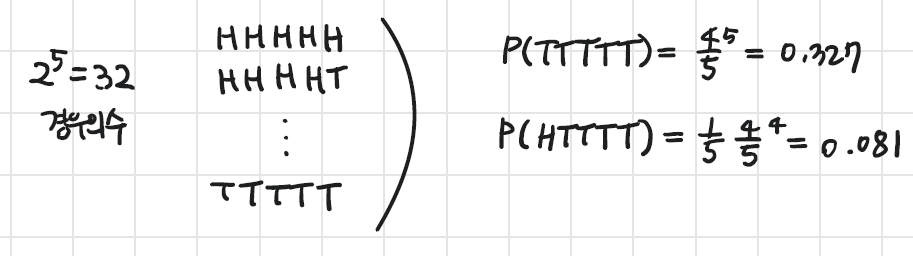
잘 보면,
P(T=5,H=1)=455=0.327
P(T=4,H=2)=15454×5=0.409
Tail이 4번 나올 확률이, 5번 나올 확률이 높은 걸 확인할 수 있다. 그래서 모두 계산해보면,
L=100일 때로 높여보면,
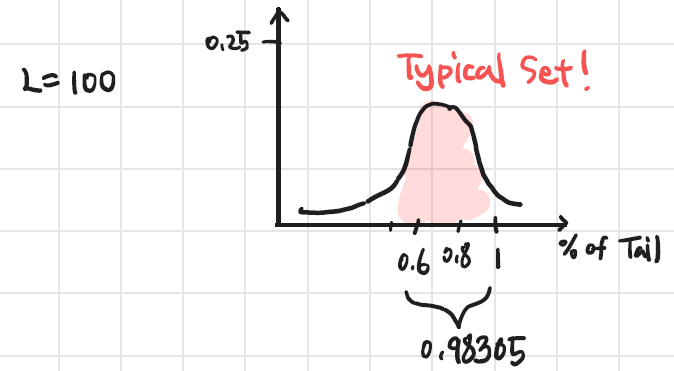
즉 sequence가 길어질수록 확률적으로 주로 발생하는 친구들이 정해진다는 것을 알 수 있다. 그리고 이런 친구들을 Typical set이라고 부르는 것이다.
그럼 L=5일 때, typical set 중 하나인 P(TTTTH)를 다시 계산해보면,

뭔가 의심스러우니 여러 상황에 대해서 계산해보자.
- L = 100
- T = 80 and 79
- H = 20 and 21
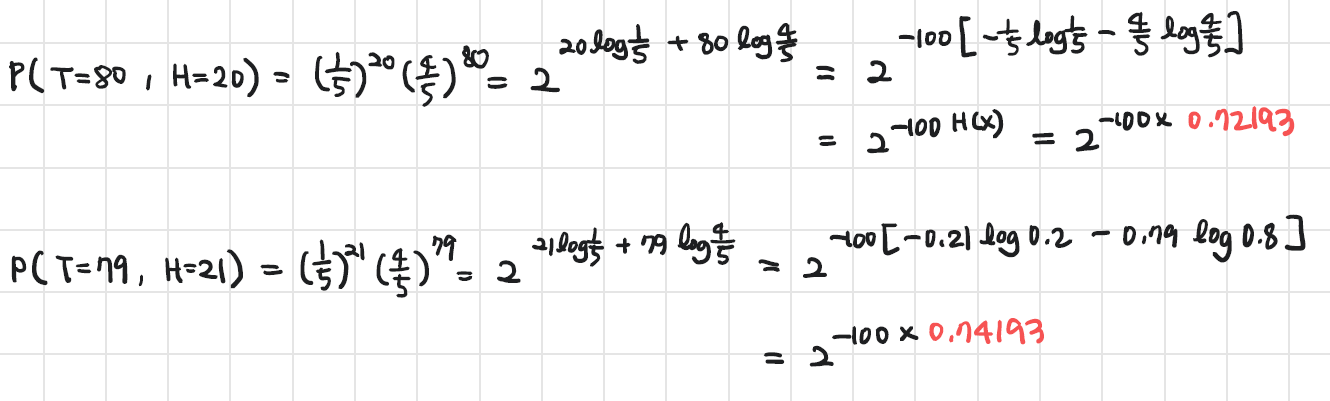
따라서,
P(80T,20H)=2−100×0.72193
P(79T,21H)=2−100×0.74193
서로 다르지만, 거의 비슷하며 L→∞인 경우 두 Prob.은 유사해짐을 알 수 있다. 이렇게 대수의 법칙에 근거하여 typical set을 다루는 것을 AEP라고 한다.
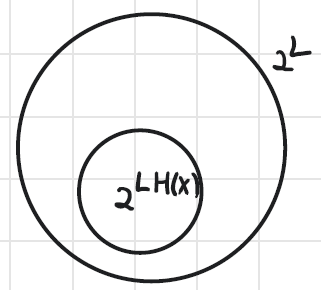
Typical set의 size
Typical set에 속하는 seq.들의 확률의 합은 거의 1에 근접할 것이다.
P(seq1)+P(seq2)+...+P(seqn)≤1
P(seqi)=2LH(X)이므로 위의 식을 잘 정리해보면,
Ntypical×2−LH(X)≤1
따라서 # of typical set은 2LH(X)보다 작거나 같음을 알 수 있다.
그래서 L=100일 때, 아까의 상황을 가정하면,
NT≤2100×0.72..≤273
전체 sequence의 수는 2100이다.
Data compression
위의 성질을 생각해보면, 데이터를 압축하는 데에 AEP를 사용할 수 있다.
A가 B에게 100번의 Toss 결과를 data로 제공하는 경우를 생각해 봤을 때, 얼마나 많은 bit가 필요한지 생각해보자.
전송하는 대부분의 toss sequence는 확률상 typical set에 포함된다. 그리고 4개의 알파벳을 전송하는 데 필요한 bit 수는 log4=2로 2bits임을 알 수 있다.
따라서 typical set에 대해서는
log2LH(X)=LH(X)=100∗0.72..=73으로 73bits가 필요하다.
Typical set이 아닌 경우에 대해서는
log|X|=log2L=L=100으로 100bits가 필요하다.
A에서 B로 데이터를 전송할 때, typical set인지 아닌지 표현하는 prefix bit까지 포함하면 다음의 bit가 필요하게 된다.
- Typical set: 73+1
- Non typical set: 100+1
대부분의 경우 typical set이기 때문에, 100bits짜리 데이터를 73bits로 주로 보낼 수 있다는 장점이 있다. 기댓값은 다음처럼 구할 수 있다.

'Study > Coding and Information Theory' 카테고리의 다른 글
| SUMMARY (1) | 2024.04.10 |
|---|---|
| [05] Entropy Rates (1) | 2024.04.10 |
| [03-2] Jensen's Inequality (0) | 2024.04.09 |
| [03-1] Entropy, Relative Entropy & Mutual Information (0) | 2024.04.09 |
| [02] Brief review of Probability (1) | 2024.04.09 |