
딥러닝(DL)을 잘하고 싶다면, 기계학습(Machine Learning, ML)에 대한 이해가 깊으면 도움이 된다. 기본적으로는 ML의 네트워크에서 layer를 3개 이상 쌓은 것들을 DL이라고 하기 때문이다. 구체적으로는 ML에서 사람이 feature extraction을 손수 진행했던 반면, DL에서는 feature도 학습 과정에서 알아서 찾길 원한다는 차이점이 존재한다.
DL이 가장 많이 쓰이는 분야는 이미지 인식과 언어 인식이다. 이미지 인식(Image Recognition)은 이미지에서 객체를 식별하는 것이 주된 목표이고 언어 인식(National Language Processing, NLP)은 문장에서의 단어들을 가지고 해석하는 것이 주된 목표이다.
DL에서 무엇을 하는지 알기 위해, 이미지 인식과 NLP에서 대표적인 모델 학습 알고리즘인 BoW와 Word2Vec를 가지고 대략적인 개념을 이해해 볼 것이다.
Bag-of-Words, BoW

쉽게 말해서, 자주 나타나는 특징을 찾아서 분류하려는 시도이다. 사람의 얼굴을 식별하려고 할 때, 그 사람(A)의 얼굴 사진을 한장 더 학습시키는 것보다 A의 눈, 코, 입, 귀, 머리카락 등을 학습시켜서 그 사람이 A일 확률(예를 들어, 눈(50%), 코(40%), 귀(70%), 머리카락(15%))을 구하고, 이를 바탕으로 그 사람이 A인지 결정하는 방식이다.
구성 단계는 다음과 같다.
- Feature extraction
- Learn "visual vocabulary"
- Quantize features using visual vocabulary
- Represent images by frequencies of "visual words"
BoW - Feature extraction
Patch(mask)를 이용해서 이미지로부터 feature들을 얻는다. Feature를 추출하기 위해서는 Regular grid나 Interest regions을 탐색하거나 SIFT(Scale-Invariant Feature Transform)를 이용한다.
BoW - Learning the visual vocabulary
추출된 feature들을 학습시켜서 Classify한다. 해당 feature를 종류별로 나타내는 과정이다. 눈, 코, 입 등으로 보이는 듯한 feature를 분류하는 과정이라고 생각하면 된다.
BoW - Quantize the visual vocabulary

Clustering 결과에서 가장 대표되는 feature를 선택하는 과정이다. 이렇게 선택된 feature를 visual vocabulary라고 하며, 해당 이미지를 가장 잘 나타내는 feature가 된다.
BoW - Result
SIFT, Scale-Invariant Feature Transform
비슷한 feaure를 matching하여, 같은 feature를 나타내고 있음을 나타낸다.
BoW evaluation
| Pros | Cons |
| - compact summary of image content - good results in practice |
- background & foreground mixed - similar color histogram image - optimal vocabulary? |
Extension of BoW
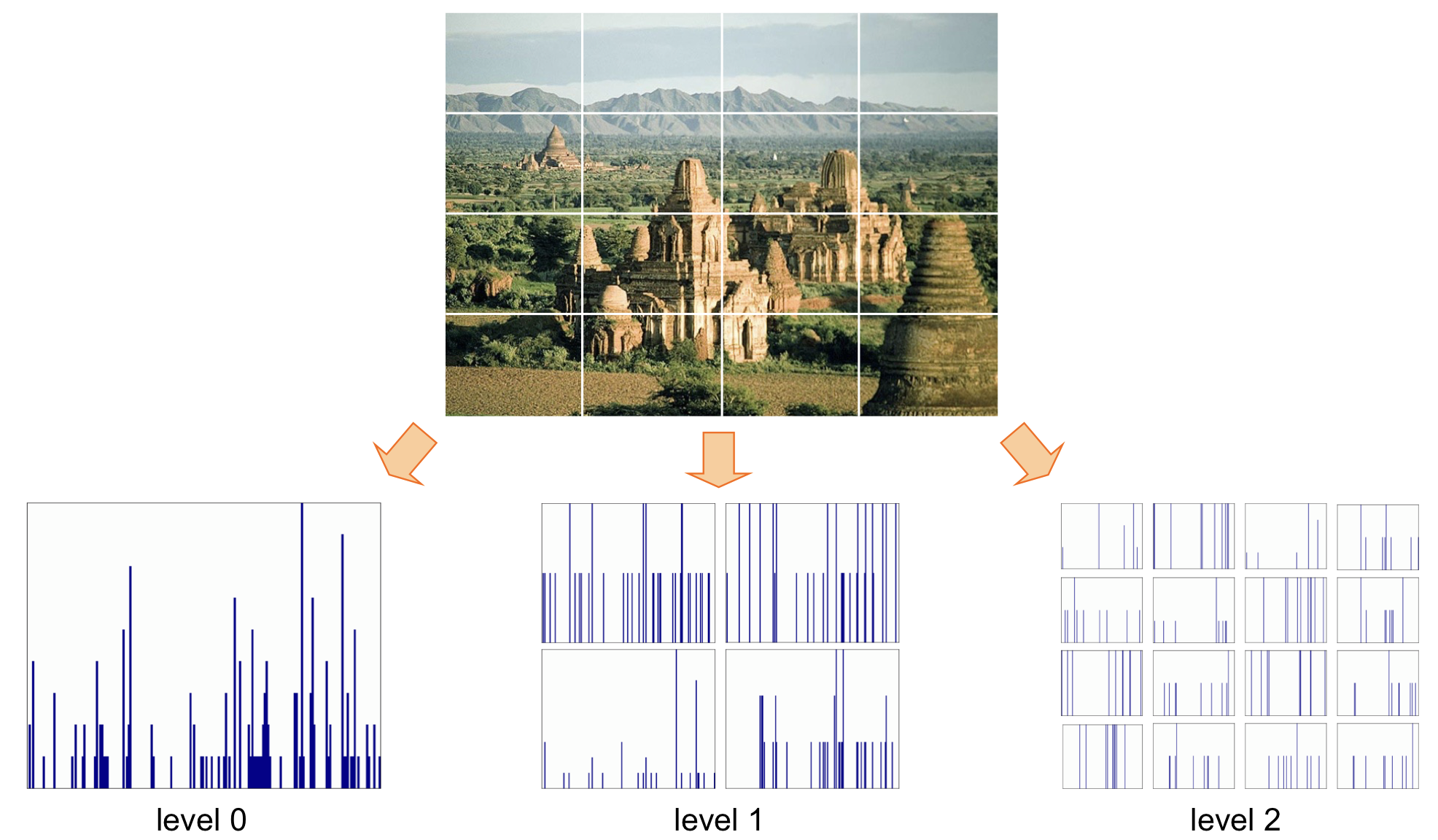
Several resolution에서의 결과를 바탕으로 이미지 인식을 진행하기도 한다.
Word2Vec

단어를 vector화 해서 비슷한 의미의 단어들끼리 근처 영역에 두겠다는 방법이다. 예를 들어, [강아지, 고양이, 토끼]가 비슷한 영역에, [사과, 배, 귤]이 비슷한 영역에 위치할 수 있다.
처음에는 one-hot vector로 표현하려고 했다. 하나만 1이고 나머지는 0인 vector이다. Vector의 dimension은 vocabulary word의 수라고 보면 된다.
motel = [0 0 0 0 1]
hotel = [0 0 0 1 0]
이렇게 했을 경우, 문제가 발생한다. 인터넷에서 검색을 하게 될 경우, 우리는 일반적으로 "S hotel"의 검색 결과가 "S motel"의 검색 결과를 함께 보여주길 원한다. 하지만 one-hot vector의 경우 두 vector가 orthogonal하기 때문에 연관성을 찾기 어려워진다.
이에 대한 해결책으로 문장에서 target word 주변의 word에 가중치를 줘서 vector화하는 방법이 제시되었다. 단어간의 가중치는 ML의 Encoding 방법으로 찾을 수 있다.
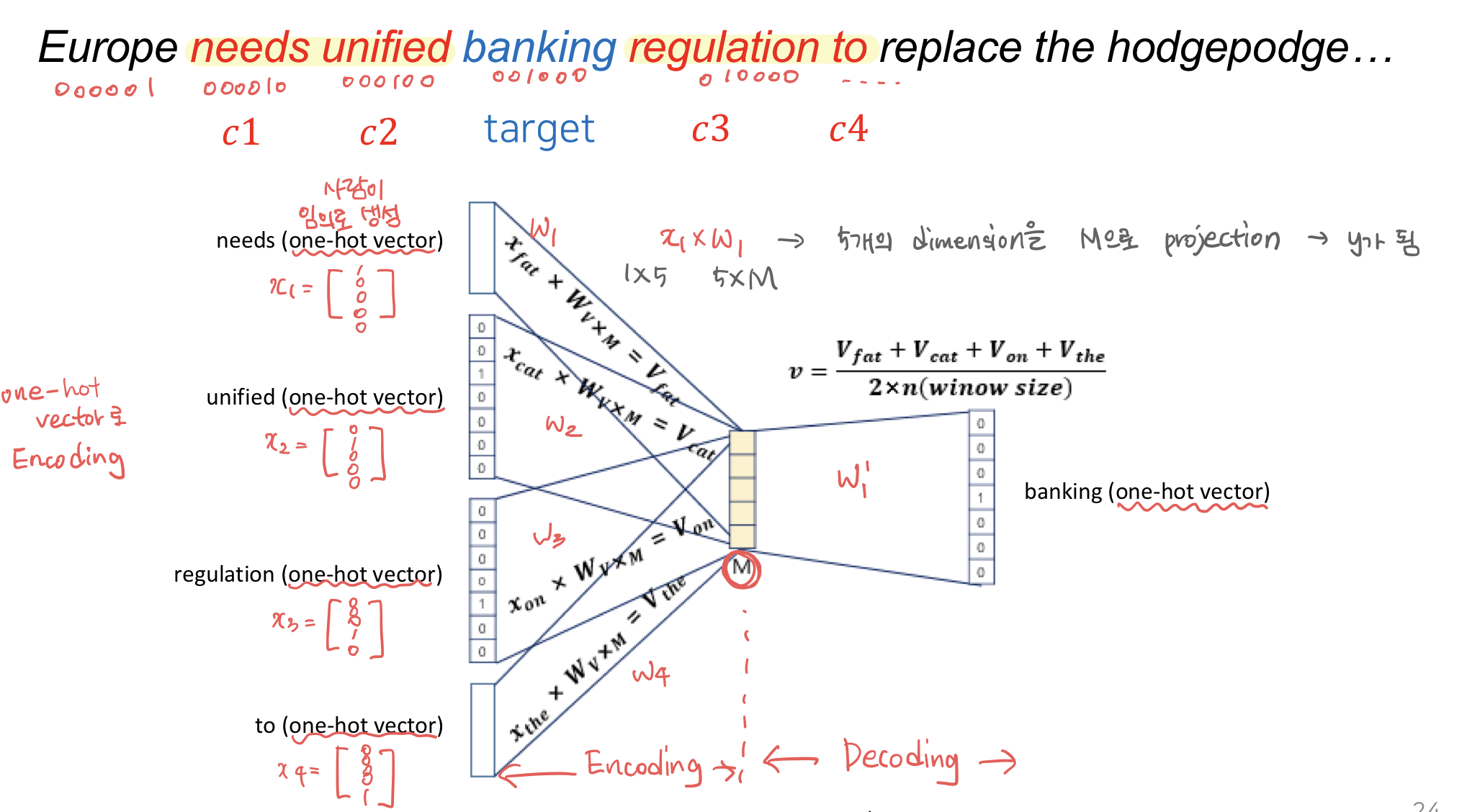
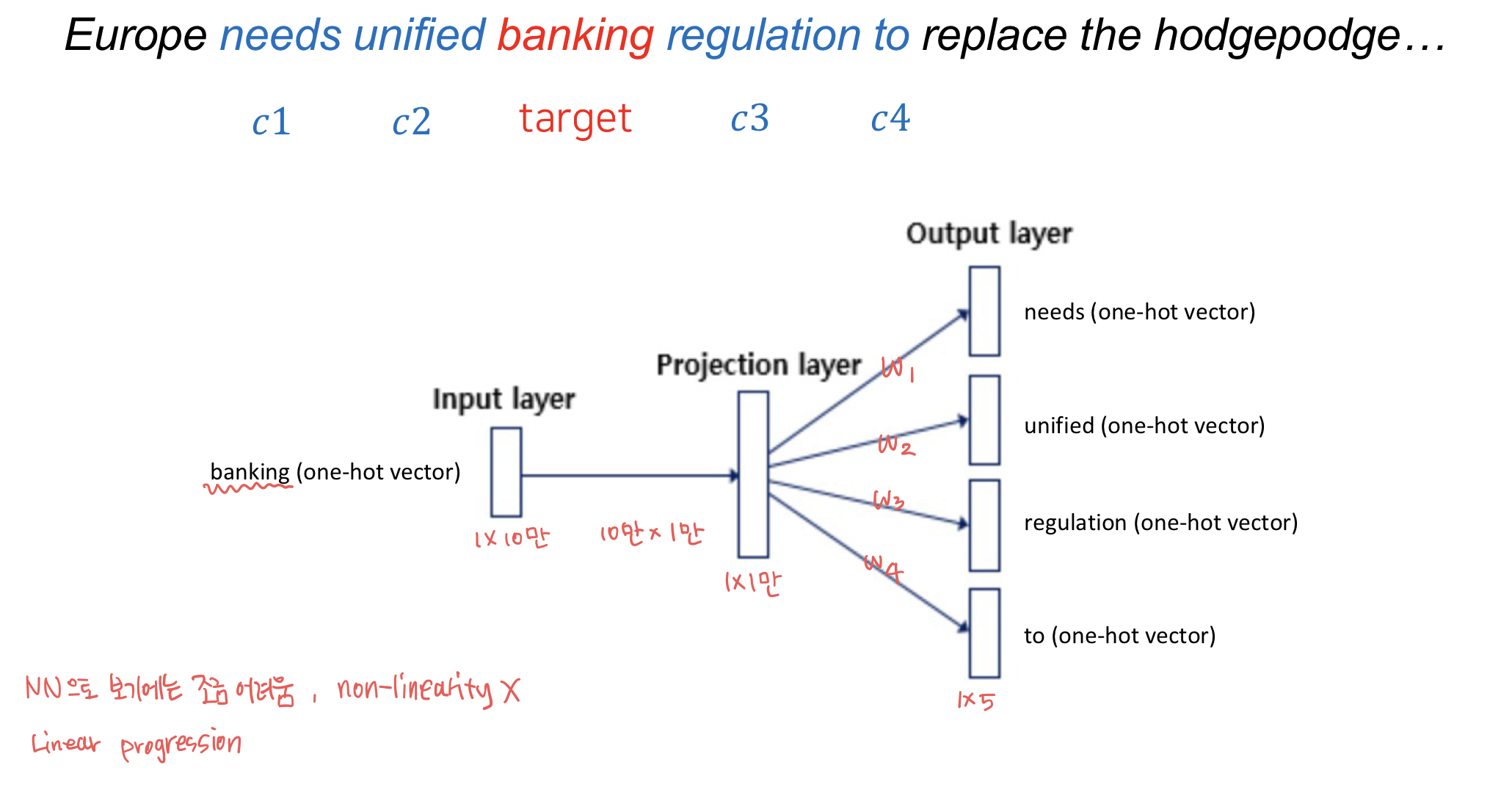
학습된 최종 vector를 space 위에 표현하면 다음과 같다.
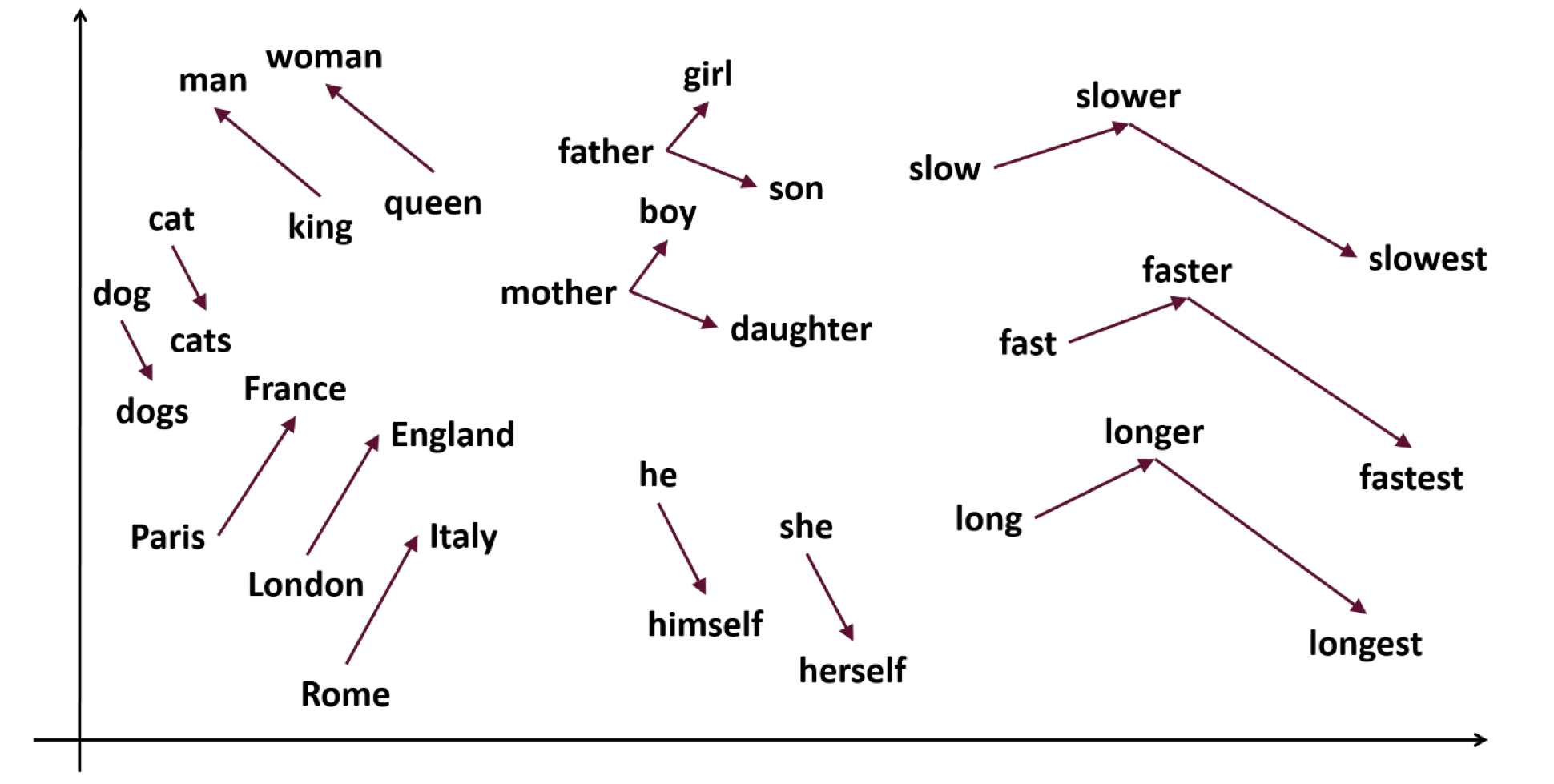
Vector를 따라 단어를 확인해 보면, 실제 의미와 유사하게 단어간의 관계가 나타나는 것을 확인할 수 있다.