
CPU virtualization에는 크게 2가지 개념이 중요하다. 1번 포스트에서 다루었던, context switch랑 scheduler(스케쥴러)이다. Context switch는 방법론적인거고 scheduler는 정책적인 내용이다.

간단하게 자주 사용하는 용어부터 알아본다.
- Workload: 해야되는 프로세스(어플리케이션)의 양
- Scheduler: ready process를 실행할 타이밍 결정하는 방법
- Metric: 평가방법
스케쥴링의 목표(=평가 요소)는 다음과 같다.

| Turnaround time | completion_time - arrival_time (minimize) |
| Response time | initial_schedule_time - arrival_time (minimize) |
| Throughput | completed_jobs / unit time (maximize) |
| Resource utilization | 자원 다 쓰기 (maximize) |
| Overhead | Context switch 최소화 하기 (minimize) |
| Fairness | 모든 job 같은 수만큼 수행하기 (maximize) |
그럼 이제 스케쥴링 방법에 대해 알아볼 건데, 개념적 이해를 쉽게 하기 위해 다음의 가정을 한다.
- 모든 job은 same time 동작한다.
- 모든 job은 동시에 arrive한다.
- 모든 job은 CPU만 사용한다.(I/O 없음)
- 모든 job의 runtime은 미리 알고 있다.
FIFO(First-In-First-Out)

Job이 들어온 순서대로 실행하는 방법이다. Turnaround time을 계산해 보면, 다음과 같다.

" Turnaround time = Completed - Arrived "이므로 평균을 내면 (10+20+30)/3 = 20s이 된다.
Convoy effect
좋은 방법 중 하나이지만, 가령 job의 필요한 runtime이 다를 경우 성능이 감소할 수 있다. 아까의 가정에서 job의 runtime 가정을 지워보자
모든 job은 same runtime 동작한다.- 모든 job은 동시에 arrive한다.
- 모든 job은 CPU만 사용한다.(I/O 없음)
- 모든 job의 runtime은 미리 알고 있다.

FIFO를 사용하게 될 경우 (60+70+80)/3 = 70s가 된다. runtime이 가장 긴 A를 먼저 실행하게 되면서 B와 C의 turnaround time이 커지게 된 것이다. 이를 해결하고자 제시된 것이 SJF(shortest job first) 기법이다.
SJF(Shortest Job First)
방금의 경우에 runtime이 짧은 친구부터 실행하면 어떻게 될까?

Turnaround time은 (10+20+80)/3 = 36.7s가 되어 훨씬 짧아지는 것을 알 수 있다.
이제 앞에서 했던 가정 중에, 모든 job이 동시에 arrive하는 가정을 지워보자.
모든 job은 same runtime 동작한다.모든 job은 동시에 arrive한다.- 모든 job은 CPU만 사용한다.(I/O 없음)
- 모든 job의 runtime은 미리 알고 있다.
그러면 위의 문제는 다음과 같다.
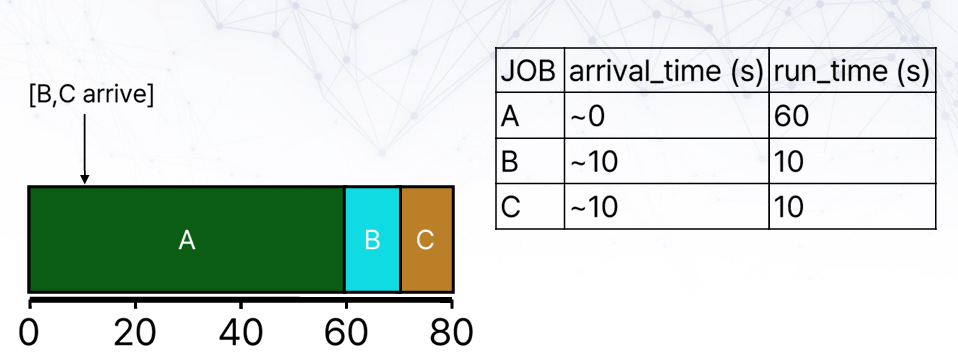
실행 중인 job을 중지하지 않으므로 FIFO와 같은 결과를 가지게 된다. 새로운 job이 arrive했을 때, 실행 중인 job을 중단하고 다시 스케쥴링하는 방법을 Non-preemptive SJF, 혹은 STCF(Shortest Time-to-Completion First)라고 한다.
Non-preemptive SJF or STCF(Shortest Time-to-Completion First)
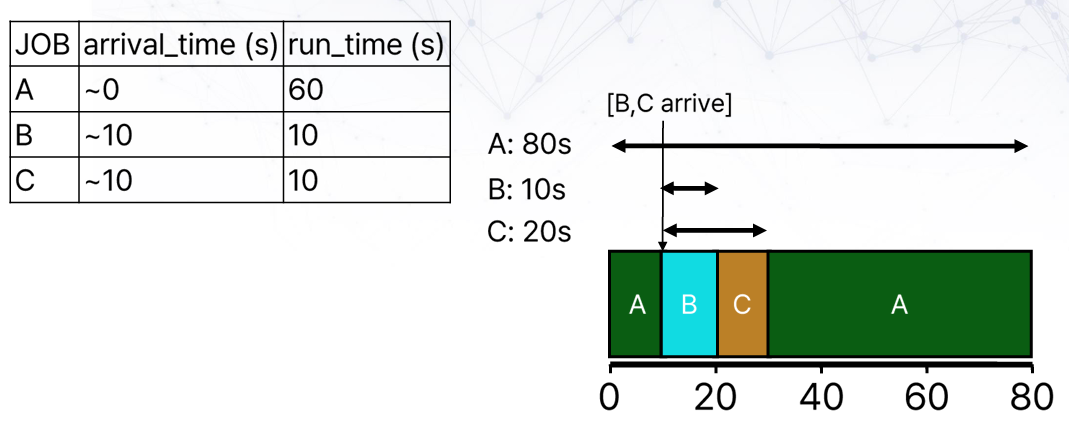
STCF의 turnaround time은 (80+10+10)/3 = 36.7s로 기존과 동일해진다.
Response vs Turnaround
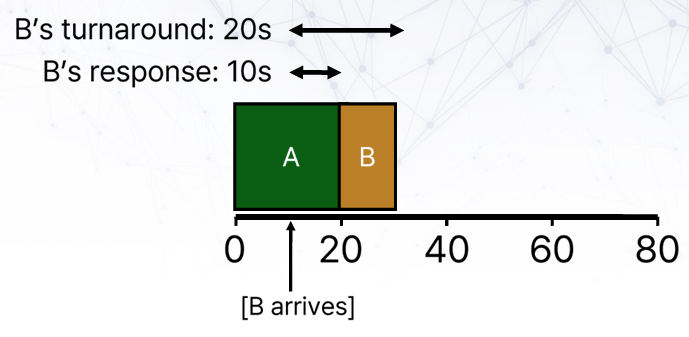
지금까지는 metirc으로 turnaround time 하나만 봤다면, 이제는 response time도 생각해 볼 필요가 있다. Job이 언제 끝나는 것만큼 중요한 것이 언제 시작하는지 이기 때문이다.
RR(Round-Robin)
계산해 보면 알겠지만, FIFO, SJC, STCF 모두 response time에서는 좋지 못하다. 이를 해결하고자 나온 것이 RR 스케쥴링이다. 모든 job을 specific time으로 쪼개서 번갈아 가면서 실행하는 방법이다.
STCF(FIFO)와 비교해 보면 다음과 같다.
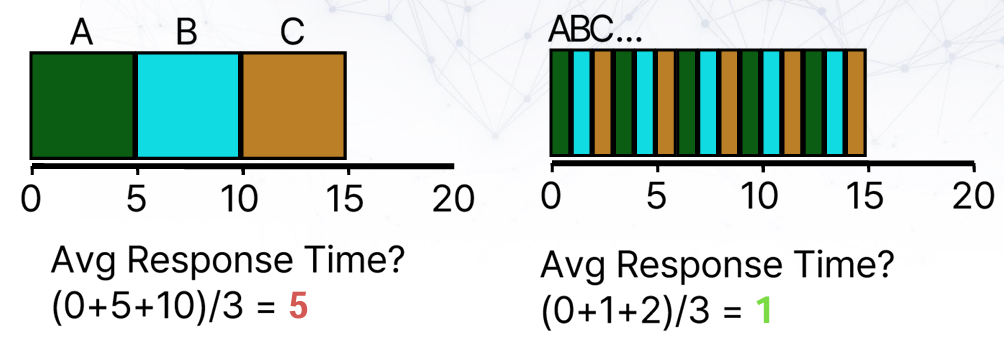
Response time은 많이 줄어들었는데, 대신 turnaround time은 많이 늘었다. STCF 10s에서 RR (15+14+13)/3 = 14s로 증가했다. RR은 쓰레기인가?라고 할 수 있겠지만, 실제로는 우리가 job의 runtime이 얼마나 될지, 얼마나 다를지 알 수 없기 때문에 RR은 좋은 스케쥴링 방법이다.
Real environment
실제 상황에서는 우리가 앞서했던 가정이 모두 존재하지 않게 된다.
모든 job은 same runtime 동작한다.모든 job은 동시에 arrive한다.모든 job은 CPU만 사용한다.(I/O 없음)모든 job의 runtime은 미리 알고 있다.
가령 CPU I/O 정보가 없다면, job이 CPU를 사용하지 않고 있음에도 다른 job을 할 수 없어 CPU 자원 손해가 커지게 된다. 또한, runtime을 모르기 때문에 STCF와 같은 방법은 사용할 수 없게 된다.
어쨌든 turnaround time과 response time 모두 잘 보장해 줄 수 있는 스케쥴러가 필요하게 된다. 살펴볼 스케쥴러는 다음과 같다.
- MLFQ(multi-level feedback queue)
- Lottery
MLFQ(Multi-Level Feedback Queue)
일반적으로 잘 동작하는 스케쥴링을 목표로 만들어진 것이 MLFQ이다. 일반적으로 프로그램은 2개 정도로 구분해 볼 수 있다.
- Interactive program
- Batch program
Interactive program의 경우, response time이 중요할 것이고, batch program의 경우 turnaround time이 중요할 것이다. MLFQ는 이 두 목표를 모두 달성하기 위해 multi-level의 RR을 사용한다.
Priorities
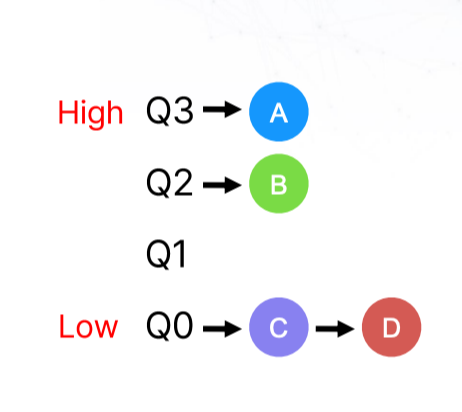
Level이 곧 priority가 된다. Higher priority를 우선 동작하며, priority가 같은 경우에는 RR을 수행한다. Priority는 일단 높게 주고, history가 쌓이게 되면, history를 보고 level을 정하게 된다.
RULEs
- Priority(A) > priority(B), A 돌리기
- Priority(A) == priority(B), RR 돌리기
- Priority는 top level에서 시작
- 오랫동안 동작할 경우, low level로 보내기
합리적인 룰이지만, 2가지 문제가 발생할 수 있다.
- Starvation
- Gaming
Problem1. Starvation
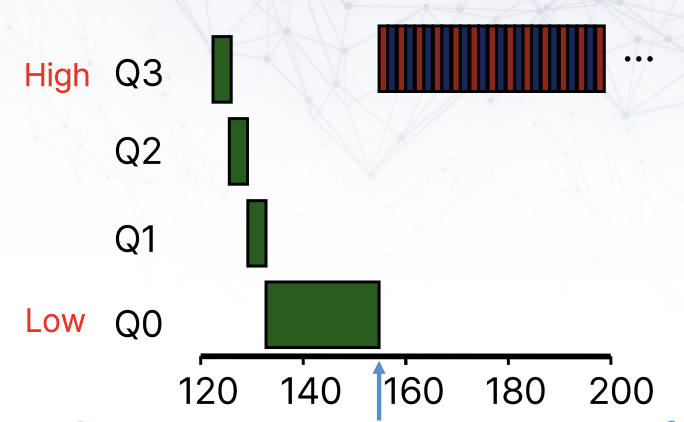
Interactive job이 있을 경우, long time job은 CPU 권한을 획득하지 못하게 된다. 해결책은 생각보다 간단하다. 일정 주기마다, 프로세스의 priority를 top으로 올리면 된다. 이를 Periodic boost라고 한다.
Problem2. Gaming
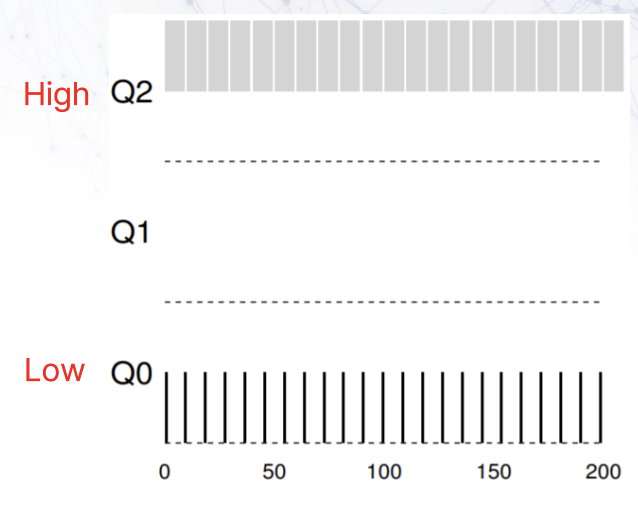
얌체같은 프로세스가 타이밍을 계산해서 강등당하기 직전에 I/O를 통해 priority를 유지할 수 있다. 이 경우에도 해결책은 간단하다. 프로세스의 total run time을 계산해서 level을 강등시키면 된다. 이를 Better Accounting이라고 한다.
Lottery Scheduling
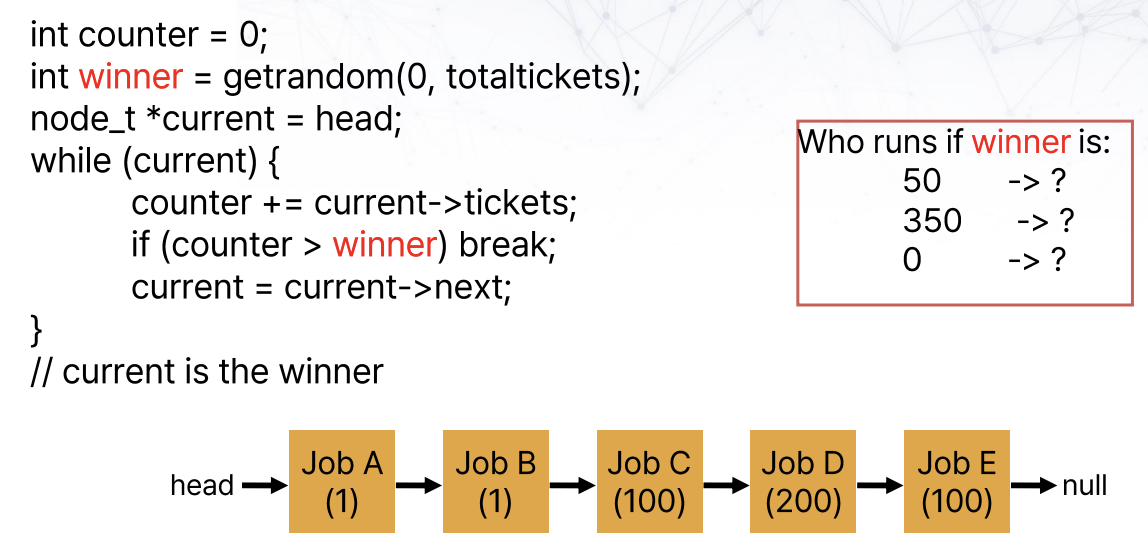
이름에서 알 수 있듯이, 확률적으로 동등하게 기회를 주는 방법이다. 프로세스에게 티켓을 주고, 해당 티켓이 뽑히면 해당 프로세스가 동작하는 방식이다. 높은 priority를 가질수록, 많은 티켓을 가지게 된다. 생각보다 잘 동작해서 실제로 사용하는 경우도 있다.
위 경우에, 50이라면 C가, 350이라면 D가 E가, 0이라면 A가 winner가 된다.
Multiprocessor Scheduling
지금까지는 single core였는데, 이제부터는 multi-core에서의 스케쥴링 기법을 공부해 본다. Multi-core라고 무조건 빨라지는 것은 아니다. 원래 프로그램을 parallel하게 구현해야 빨라지게 된다.
Cache affinity

하나의 CPU가 돌아가는 환경을 생각해 보자. 위 그림처럼 작은 케시랑 메모리가 붙어 있을 것이다. 프로그램이 빠르게 동작하기 위해서는 자주 사용되는 데이터가 (특히)케시나 메모리에 저장되어 있어야 할 것이다. 그리고 이는 multiprocessor에서도 마찬가지이다.
핵심은 하나의 CPU에 하나의 process가 최대한 오래 동작하게 만드는 것이 성능 향상에 중요하다는 것이다. 이를 cache affinity라고 한다.
Single Queue Multiprocessor Scheduling(SQMS)
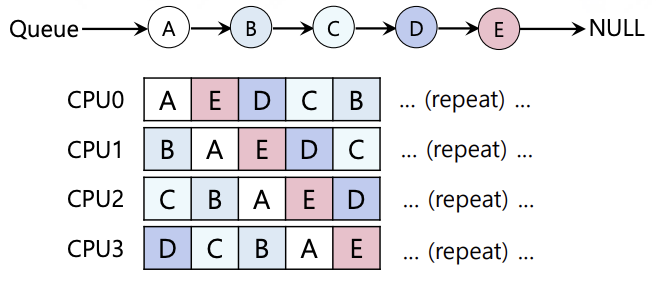
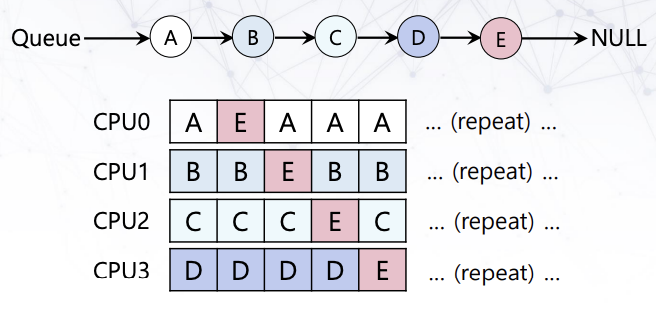
Global process queue하나를 만들고, 각 CPU에서 random으로 가져다 처리하는 방식이다. 위의 그림처럼 job이 CPU를 왔다갔다하는 cache affinity를 고려하지 못하는 단점이 있을 수 있다. 물론 아래의 그림처럼 cache affinity를 최대화하는 방식이 가능하지만, 구현하기 어렵다.
Multi-queue Multiprocessor Scheduling(MQMS)
여러개의 queue가 있는데, job은 하나의 큐에만 할당되게 된다. 나머지는 SQMS와 같다.
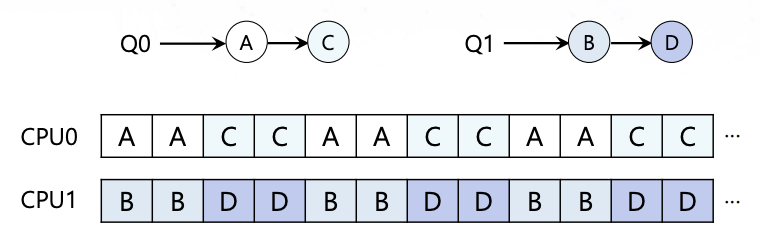
Scalability와 cache affinity를 챙길 수 있다. 다만, 하나의 queue에 있는 job이 모두 끝나게 될 경우, load imbalance 문제가 발생할 수 있다.
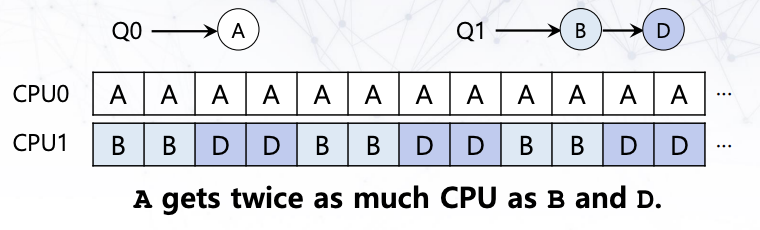
Job A마저 끝나게 된다면, CPU0는 놀게 된다. 해결책은 job을 옮기면 된다. 다만 위 경우처럼 까다로운 경우가 있다.
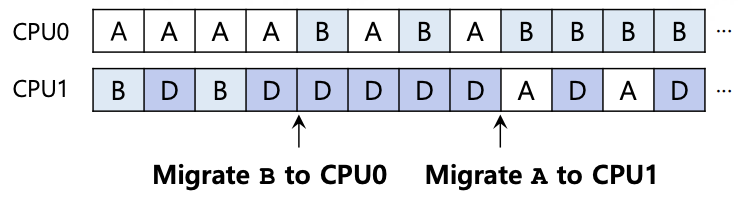
이를 work stealing이라고 하며, job이 적은 큐에서 상대적으로 많은 큐의 job을 가져오게 된다. 다만 위의 경우처럼, migration이 자주 발생할 경우 overhead가 발생할 수도 있다.
'Study > Operating System' 카테고리의 다른 글
| 6. Threads (1) | 2023.12.08 |
|---|---|
| 5. Virtual Memory (0) | 2023.12.08 |
| 4. Paging (0) | 2023.12.05 |
| 3. Memory Virtualization (0) | 2023.12.01 |
| 1. Introduction (0) | 2023.11.21 |