1.Introduction
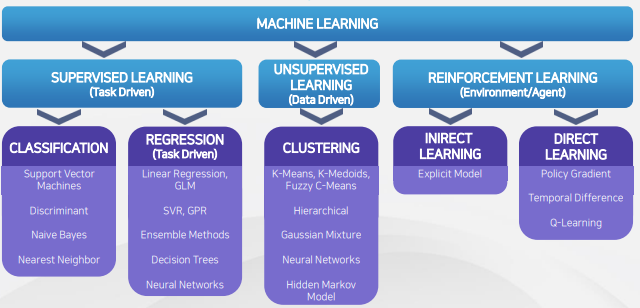
1. Types of Machine Learning(ML) 2. Sequential decision making Each time step t: Agent takes an action $a_{t}$ Environment updates with new state and emits observation, $o_{t}$ and reward, $r_{t}$ Agent receives $o_{t}$ and $r_{t}$ 3. History $h_{t}$ = $(a_{1}, o_{1}, r_{1}, ,,, a_{t}, o_{t}, r_{t})$ 4. World state Agent state와 다름. 실제 세계 5. Agent state $s_{t} = f(h_{t}) = (a_{1}, o_{1}, r_{1}, ,..
2023.05.01