
Index는 보통 자주 접근하는 파일들의 데이터 접근 속도를 높이기 위해 사용한다. 대부분의 index는 ordered files에 대해 구현되어 있다. 주로 Tree 구조를 사용한다.
Types of Index
| Primary Index | Clustering Index | Secondary Index |
| Ordering field에 대한 index Key 값의 중복이 없다. |
Ordering field에 대한 index Key 값의 중복이 가능하다. |
Non-ordering field에 대한 index 자주 검색되는 attribute를 index로 사용 |
Primary Index
Primary Key, K(i) + Pointer to disk block, P(i)
Primary Key는 주로 PK를 사용하지만, 다른 attribute를 사용할 수 있다.
Pointer는 물리적 주소/물리적 주소+offset/논리적 주소로 표현할 수 있다.
| Dense Index | Sparse Index |
| 전부를 가지고 index를 사용한다. "ABCDEF" "ABCDEE" |
일부만 가지고 index로 사용한다. "AB" "AB" |
실제로 구현한 모습은 다음과 같다.
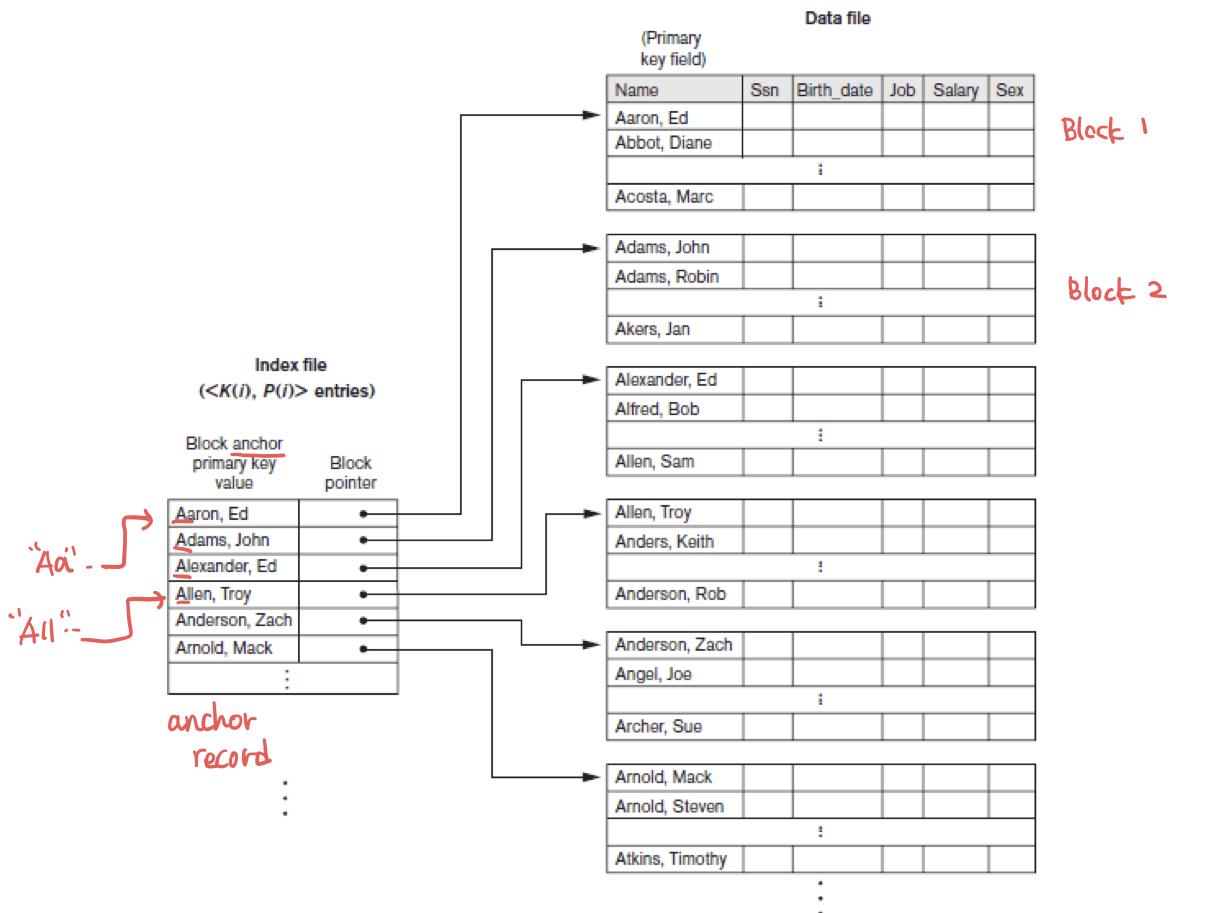
주된 문제점은 INSERT, DELETE할 때, 저장공간 관리 문제이다. 저장 공간 단위가 disk block이기에 발생할 수 있는 overflow, underflow 문제이다. Linked list 등을 이용하는 해결방법이 있다.
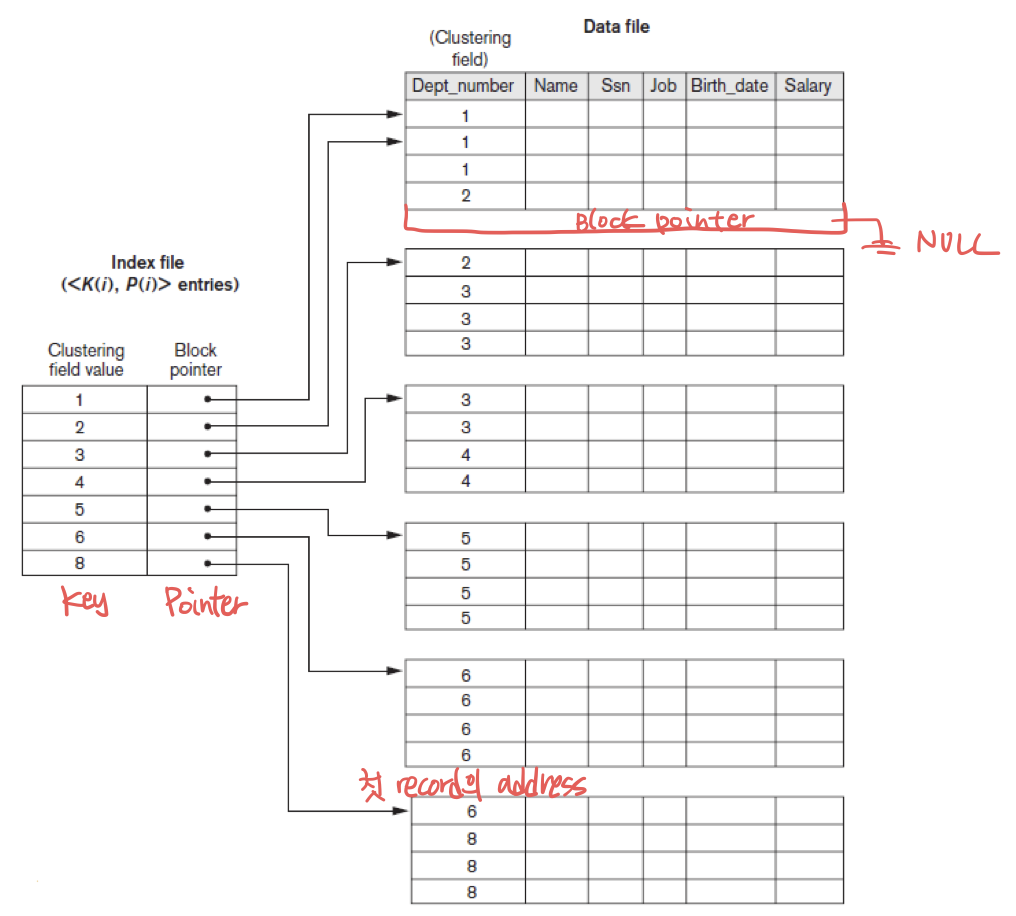
Clustering Index
마찬가지로 Key, Pointer로 구성되어 있다. 다만 중복이 가능하다. 실제 구현된 모습은 다음과 같다.
Secondary Index
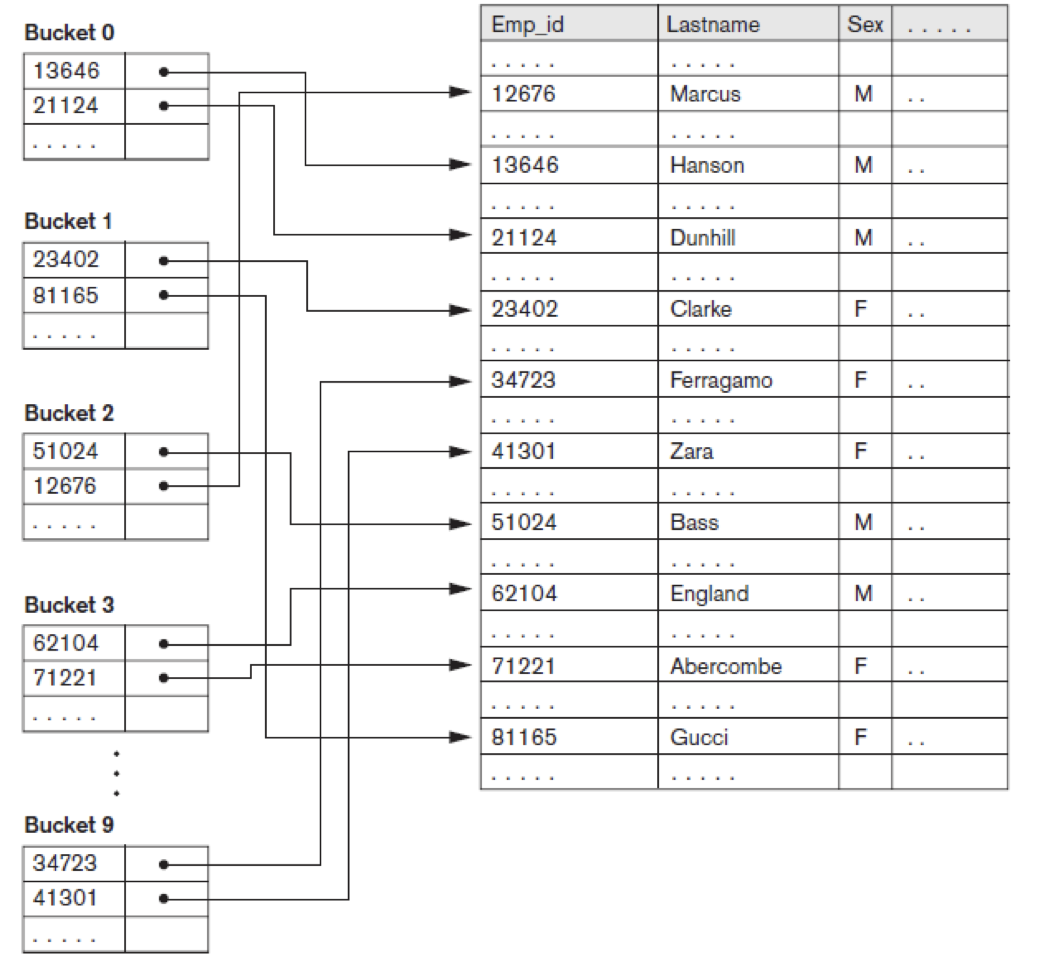
마찬가지로 Key, Pointer로 구성되어 있다. 일반적으로 Primary Index보다 더 많은 저장 공간과 더 긴 search time이 필요하다. 자주 검색되는 attrubute를 index할 때 사용한다. Dense와 Non-dense가 가능하다. 실제 구현된 모습은 다음과 같다. 일반적으로 Dense하게 구현하며, anchor가 아닌 block을 바로 가리키는 것이 특징이다.

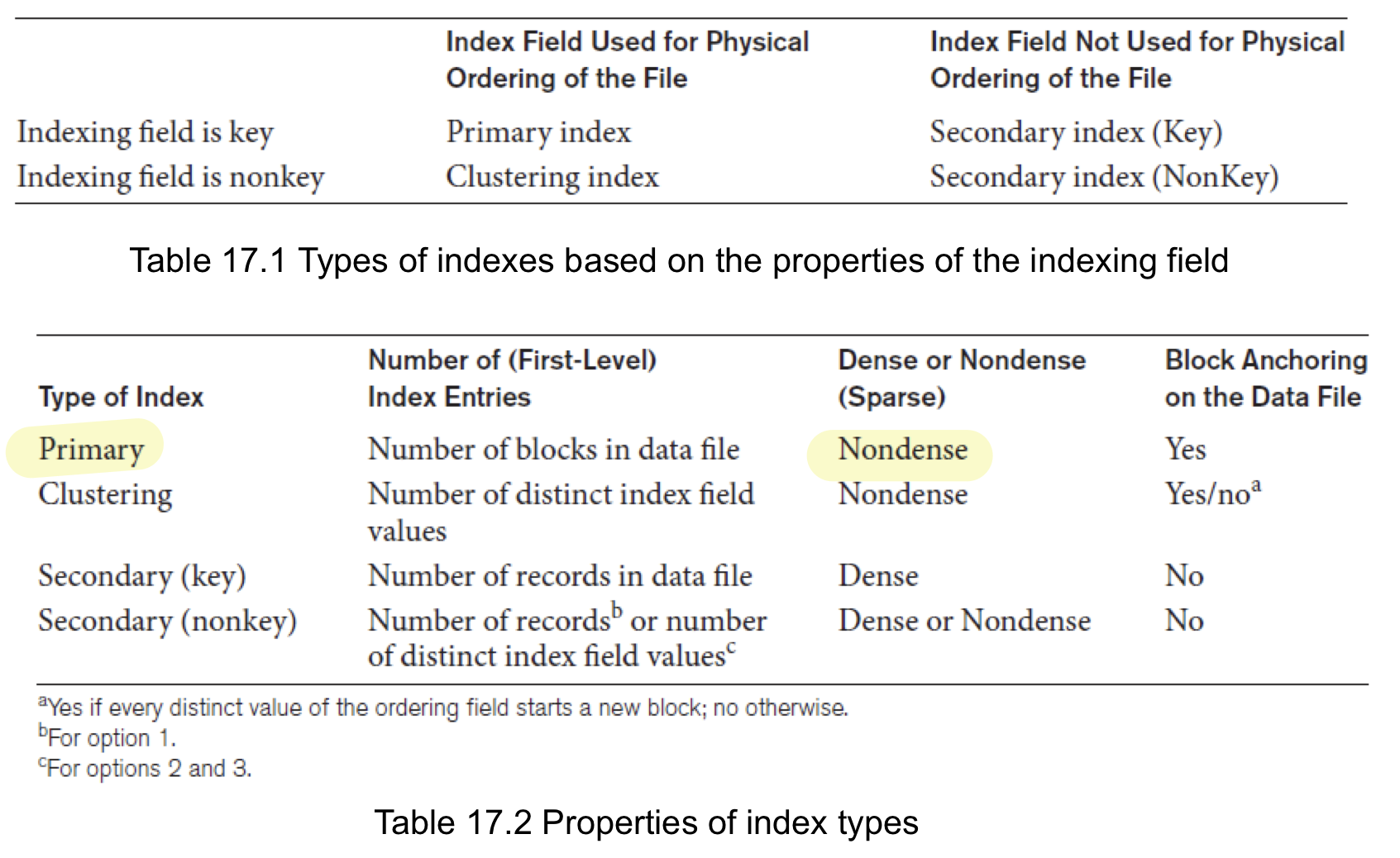
정리하면 다음과 같다.
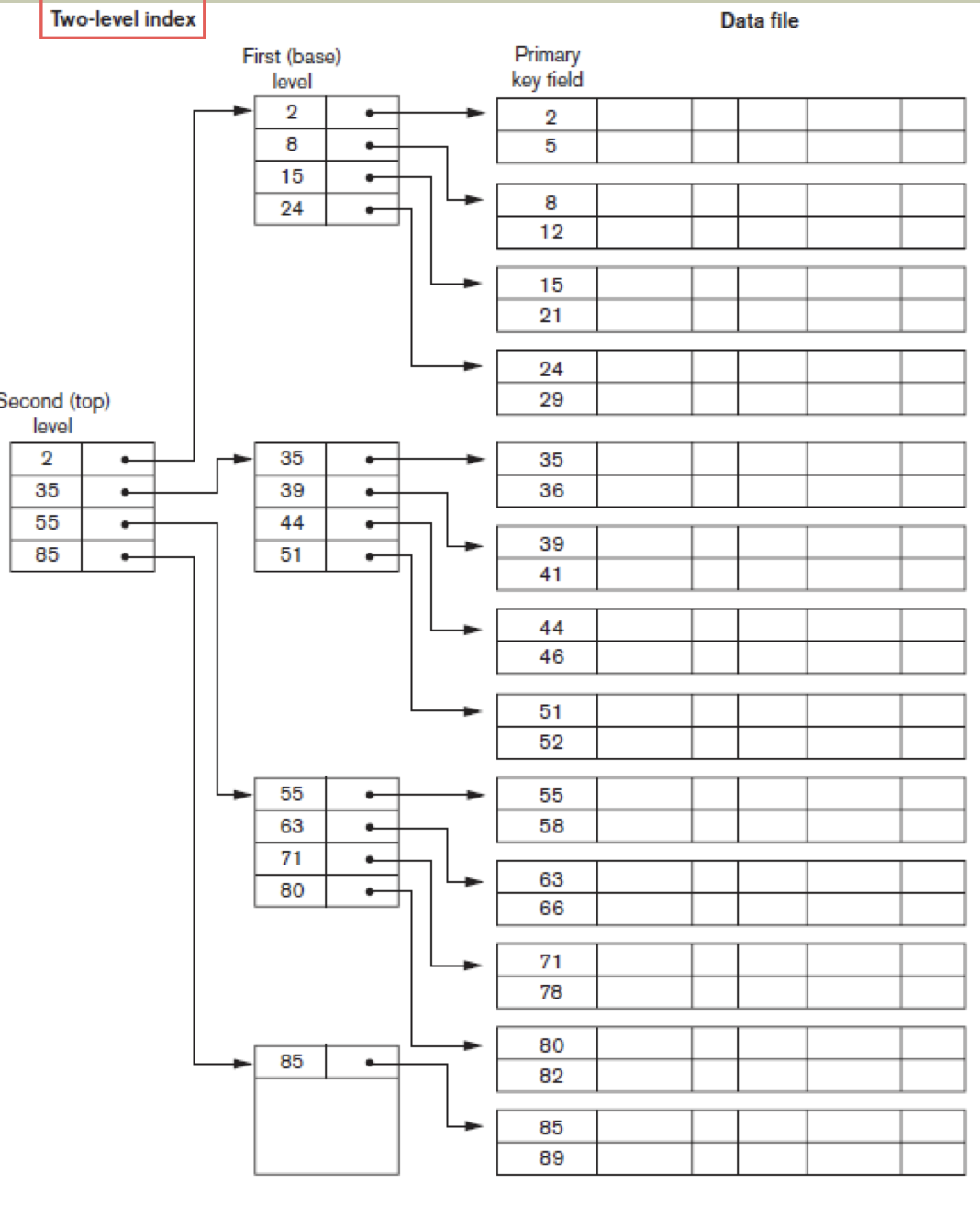
Multi-level Index
Search time을 줄이기 위해 도입되었다.
Tree
Search time이 기존의 O(n)에서 O(logn)으로 감소한다. 기본적인 Search Tree는 다음과 같다.
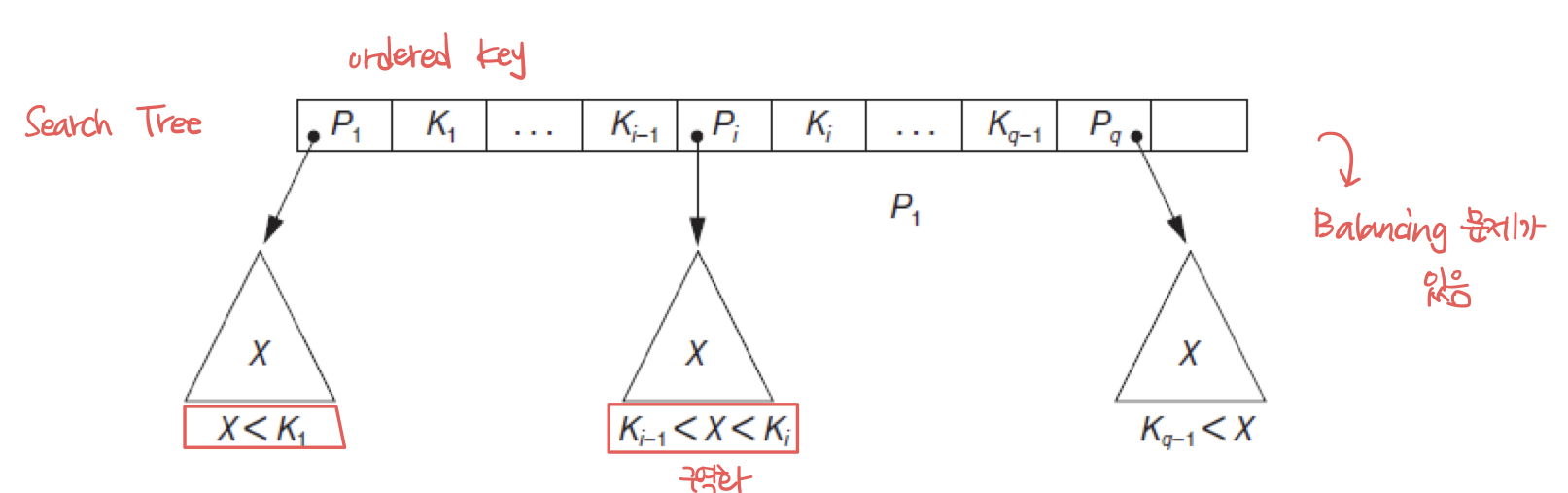
계속 data를 한쪽으로만 제공해서 tree를 키워나가다 보면, tree의 균형이 무너지는 문제를 가지고 있다. 이를 해결하기 위해 도입된 것이 Balanced tree(B tree)이다.
B tree
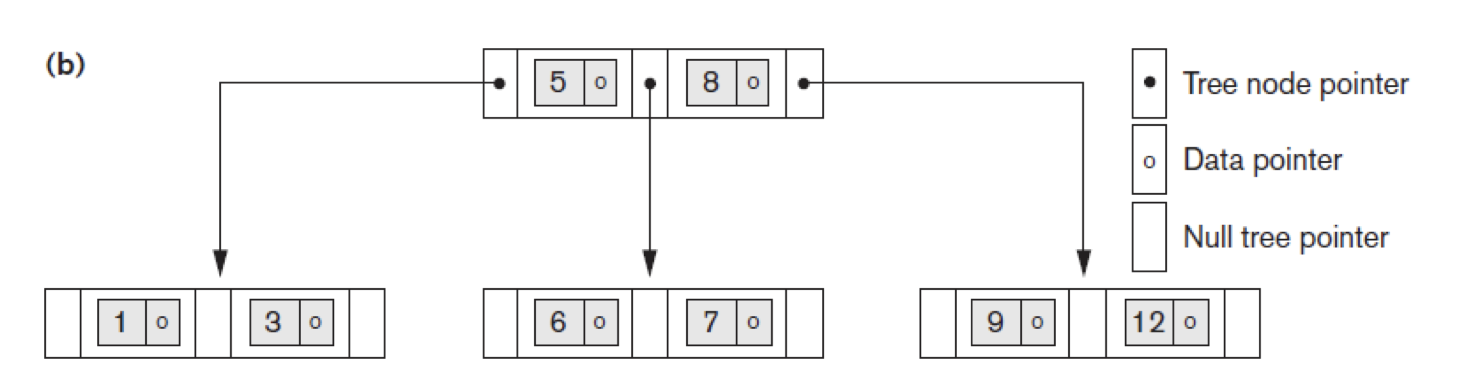
Key와 Data pointer를 같이 가지고 있는 것이 특징이다. B tree의 단점은 main memory에 다 올릴 수 없는 양의 data에 대해서 구현할 수 없는 문제가 있다. 이를 해결한 것이 B+ tree이다. 데이터를 모든 node가 들고 있는 B tree와는 다르게, B+ tree는 데이터를 leaf node에만 저장하여 많은 양의 data가 있더라도 main memory에는 key만 저장하기 때문에 대응할 수 있다.
B+ tree
구현된 모습은 다음과 같다.
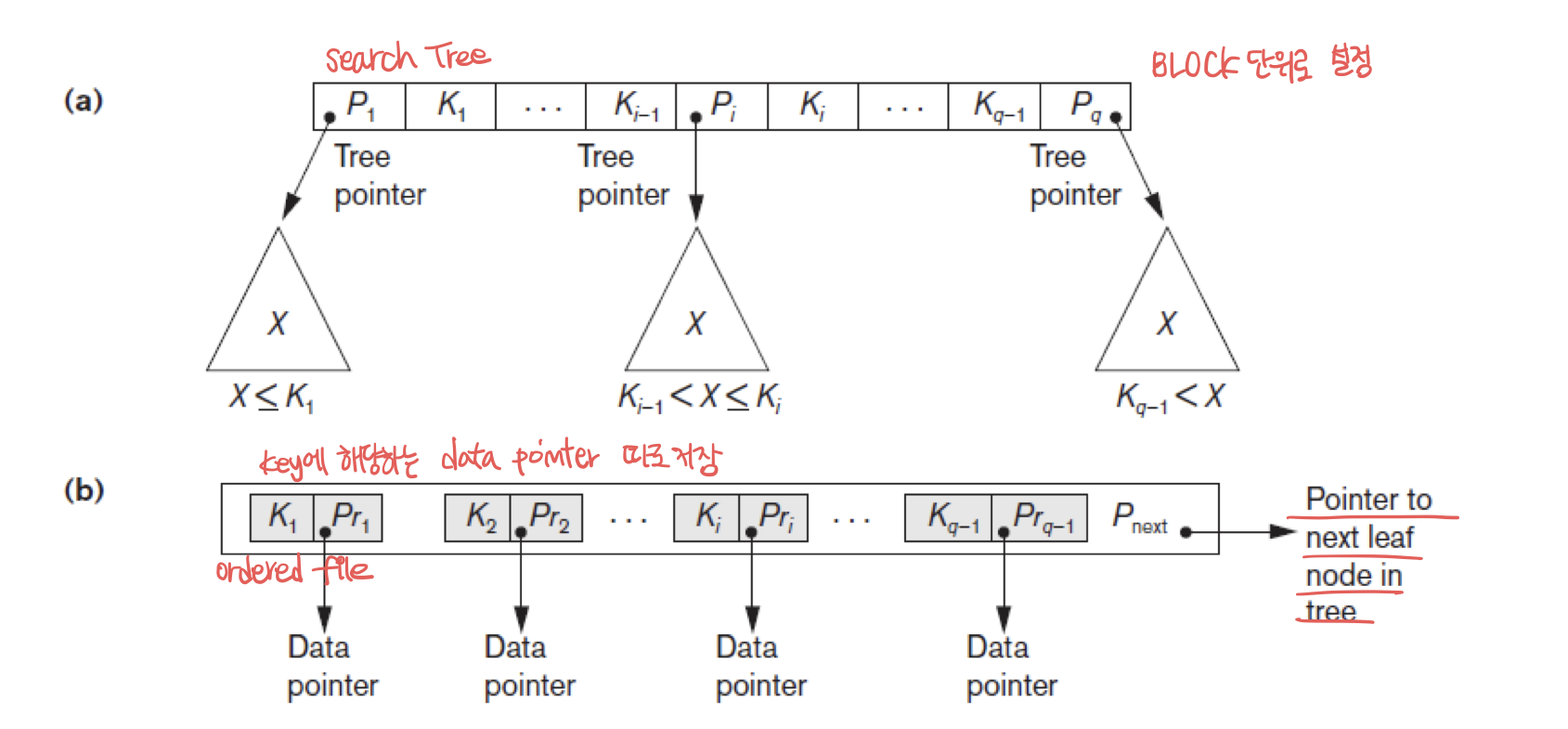
B+ tree는 order가 주어진다. Node마다 저장할 수 있는 pointer의 수를 의미한다. 만약 q=3 이라면, node마다 저장할 수 있는 key는 2가지이며, pointer는 3가지임을 의미한다.
B+ tree : INSERT
Overflow가 발생할 수 있다.
B+ tree : DELETE
Underflow가 발생할 수 있다.
Indexes on Multiple Keys
여러개의 attribute가 계속해서 요청될 수 있다. 두가지 이상의 attribute를 조합하여 key로 사용하기도 한다. Composite key라고 한다.
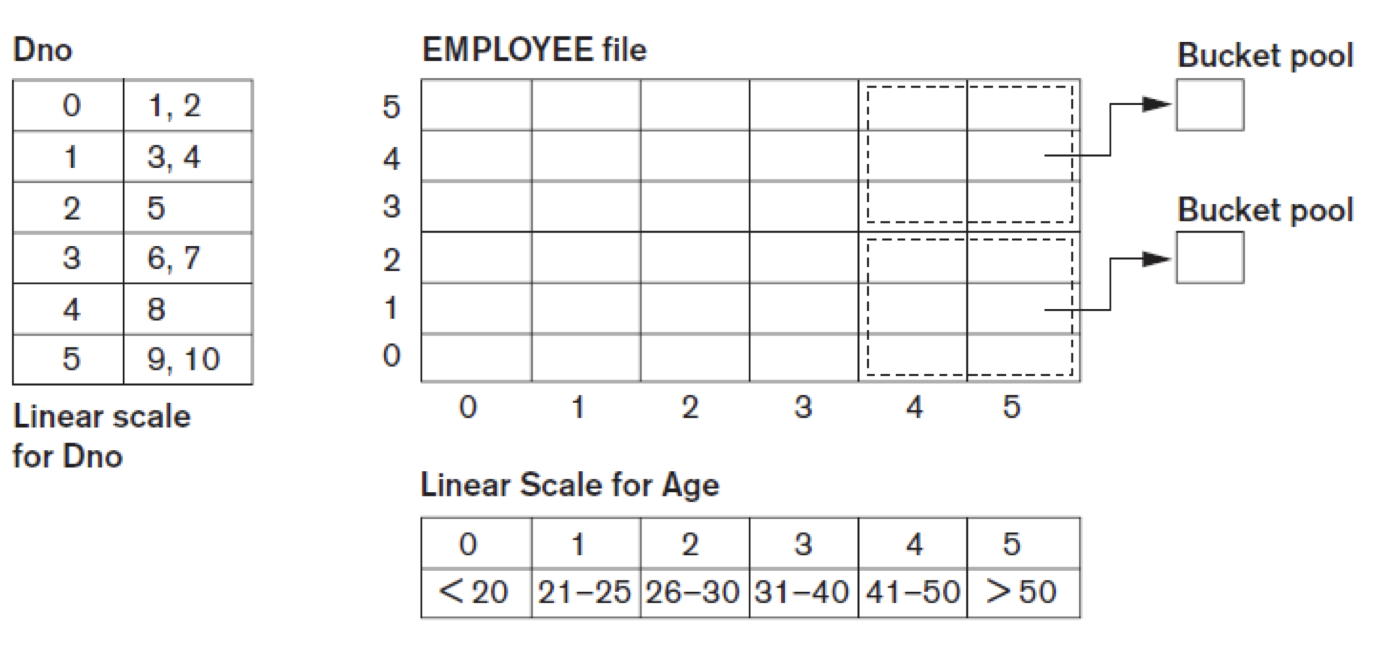
Other types of Indexes
Hash Index
Secondary structure이다. Primary data file organization을 이용하기 보다, hashing을 이용해 데이터마다 바로 접근하는 방법이다. (Key, Pointer to Record), (Key, Pointer to Block)으로 사용할 수 있다.
좋은 방법이지만, Hash collision 문제가 있다.
Bitmap Index
Row가 많을 때 사용한다. B+ tree의 Leaf node에 사용하기도 한다.
Function-based Index
CREATE INDEX upper_ix ON EMPLOYEE (UPPER(Lname))
함수의 결과물을 index로 사용할 수 있다.
General Issuses of Indexing
| Physical Index | Logical Index |
| 장점 Physical record address에 바로 접근할 수 있음 단점 Record가 바뀌면 pointer도 바뀌어야 함 |
장점 Physical record address가 바뀌어도 상관이 없음 단점 추가 연산이 필요함 |
Index Creation
CREATE [UNIQUE] INDEX <Index name> ON <table name> <column name>[<order>] [CLUSTER];
Order는 ASC, DESC가 있다.
Index of String
공간적 제약으로 인해 prefix를 사용한다.
Tuning Index
요구사항을 맞추기 위해 Index를 사용하는 방법이다. 보통은 자주 발생하는 Query의 처리 속도를 높이기 위해 사용한다.
Physical DB design in Relational DB
Good performance를 달성하기 위한 노력이다.
- DB의 Queries와 Transactions을 분석해서 효율성을 찾는다. 보통은 소수의 같은 일이 반복해서 일어난다. "80-20 rule"이 있다. 80%의 처리가 20%의 Query, Transaction에 의해 발생함을 의미한다.
- Time constraints를 분석해서 design하기도 한다.
'Study > Database' 카테고리의 다른 글
| 8. Basics of Functional Dependencies and Normalization for Relational Databases (0) | 2023.05.02 |
|---|---|
| 7. More SQL : Complex Queries, Triggers, Views, and Schema Modification (0) | 2023.05.02 |
| 5. Basic SQL (0) | 2023.05.02 |
| 4. The Relational Data Model & Relational Database Constraints (0) | 2023.05.02 |
| 3.Data Modeling Using the Entity-Relationship(ER) Model (0) | 2023.05.02 |