
7. More SQL : Complex Queries, Triggers, Views, and Schema Modification
More Complex SQL Retrieval Queries
Nested Queries
Joined Table and other join
Aggregate function
Grouping
Comparisons Involving NULL
Null의 의미는
- Unknown, 알수없는
- Unavailable, 유효하지 않은
- Not applicable, 사용할 수 없는
주의할 점은 NULL==NULL의 비교는 금지되어 있다.
대신, NULL을 확인하기 위해서 IS or IS NOT NULL을 사용한다.

SQL에서 bool은
- True
- False
- Unknown
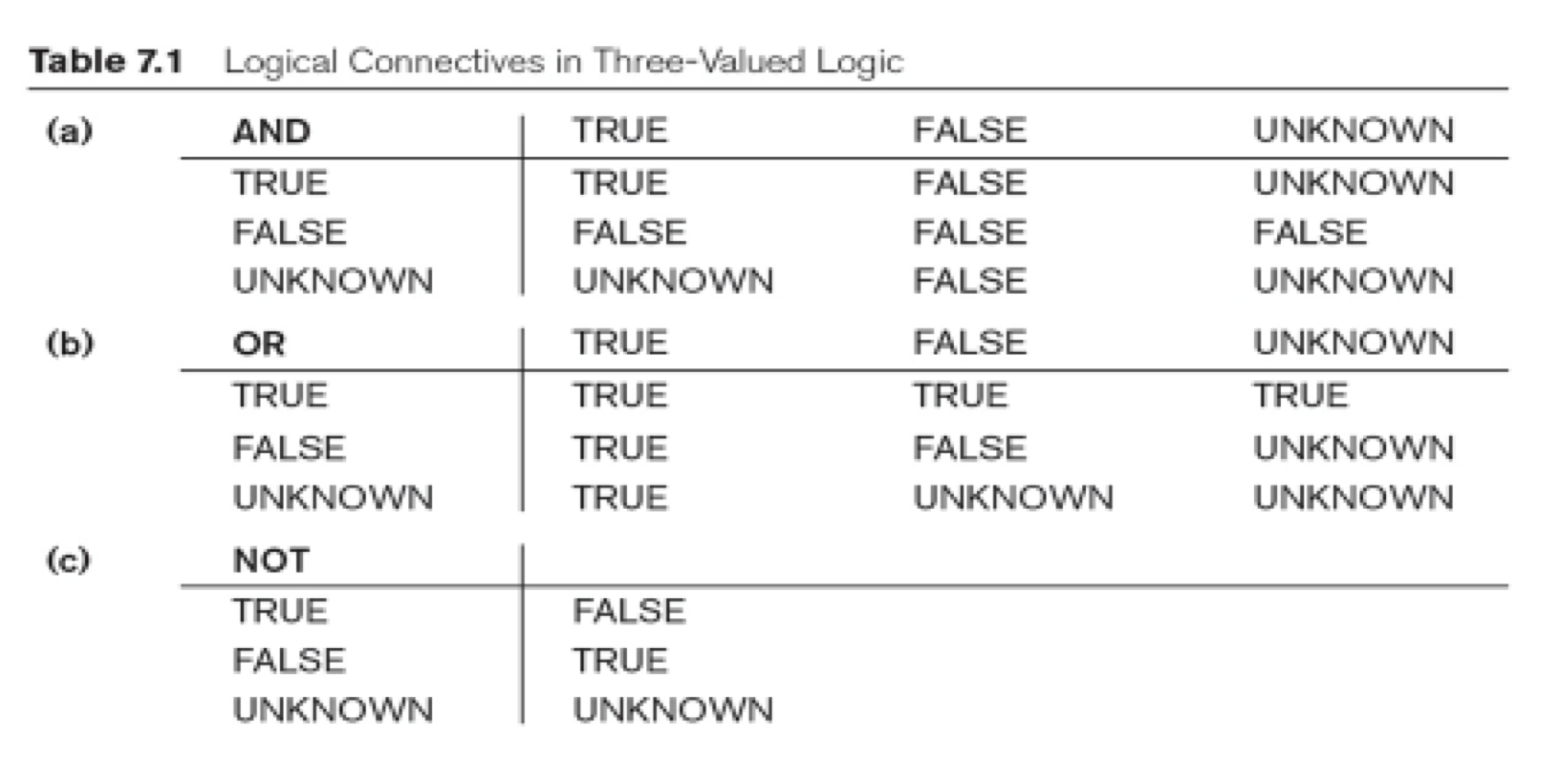
| Unknown and True = Unknown Unknown and False = False Unknown and Unknown = Unknown |
Unknown or True = True Unknown or False = Unknown Unknown or Unknown = Unknown |
Not Unknown = Unknown이다.
Nested Queries
Query를 사용할 때, WHERE에 다시 Query를 집어 넣어 사용하는 것이다. IN을 사용해 이 Query에서 나온 결과물 중에서 사용하겠다고 구현한다. 연산은 nested subquery 먼저 한다.

IN 말고도, ALL, ANY(or SOME), >, >=, <, <=, <>의 연산자를 사용할 수 있다.
ALL은 Nested query의 모든 결과를 반드시 포함할 때, 사용한다.
WHERE에는 명시적인 set, list, tuple을 사용할 수도 있다. (IN (1,2,3) 등)
간단한 구조는 아래와 같다.
SELECT [col]
FROM [table]
WHERE [expression] [operator] {ALL, ANY, SOME} (subquery)
Nested query의 attribute가 누구의 것인지 확인하기 위해서 별칭을 사용하기도 한다.

"="이나 "IN"을 사용하는 Nested query의 경우, 중첩을 하나의 Block으로 줄일 수 있다. 이를 Correlated Nested Queries라고 한다.
Correlated Nested Queries
하나의 Block으로 줄어든 만큼, 중복되는 계산이 줄어서 성능이 향상될 수 있다.
위의 Nested query는 이렇게 줄어들 수 있다.
SELECT E.Fname, E.Lname
FROM EMPLOYEE AS E, DEPENDENT AS D
WHERE E.Ssn=D.Essn AND E.Sex=D.Sex AND E.Fname=D.Dependent_name
EXISTS and UNIQUE functions for correlating queries
EXISTS : 존재하는지 True/False를 반환한다.
UNIQUE : 중복이 없으면 True, 있으면 False를 반환한다.
이 들을 사용해서 다음과 같이 Nested query를 생성할 수 있다.

Specifying Joined Tables in FROM

JOIN을 이용해서 임시적으로 tabled을 만들어 사용할 수 있다.
NATURAL JOIN, OUTER JOIN(LEFT, RIGHT, FULL)이 있다.
| NATURAL JOIN | LEFT JOIN | RIGHT JOIN | FULL JOIN |
| 겹치는 attribute로 join (default) |
왼쪽에 있는 attribute로 join | 오른쪽에 있는 attribute로 join | 양쪽에 있는 모든 attribute로 join |
Join의 경우 존재하지 않으면 NULL로 채운다.
NATURAL JOIN은 사용을 추천하지 않는다. 겹치는 attribute가 많으면, 어떤 것으로 합쳐질지 알 수 없기 때문이다.
Aggregate Functions in SQL
집계 함수는 보통 Grouping하는 경우에 SELECT, HAVING 등에서 필요하다.
COUNT, SUM, MAX, MIN, AVG 가 있다.

주의할 점은 NULL을 계산해서는 안된다.
NULL 계산의 결과는 모두 NULL이기 때문이다.
Grouping; GROUP BY, HAVING
COUNT(*)는 tuple의 수를 의미한다.
GROUP BY는 group attribute를 의미한다.
- Group attribute에 NULL이 들어오면, NULL만 따로 group해서 보관한다.
HAVING은 group에 대한 조건이다.

계산 순서는 WHERE -> GROUP BY -> HAVING 이다.

Use of CASE
일반적으로 if문이라고 보면 된다.
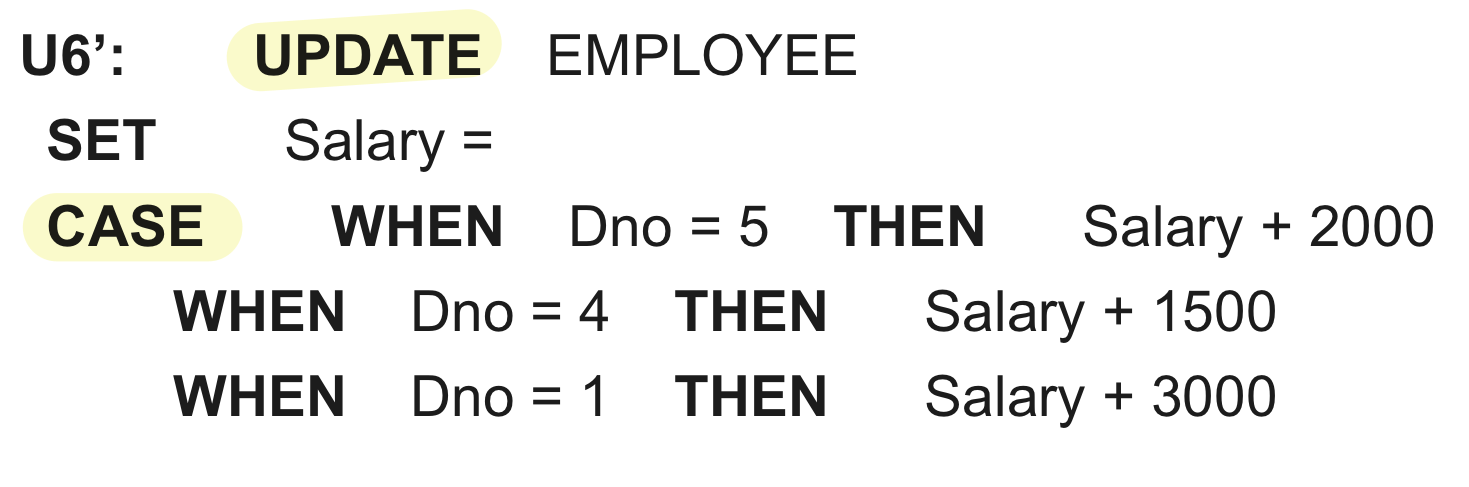
Expanded Block Structure of SQL queries

Specifying Constraints as Assertions and Action as Triggers
CREATE ASSERTION : Relational model의 제약 조건 외의 제약 조건을 생성한다.
CREATE TRIGGER : 특정 조건에서 실행할 것을 만든다. Event -> Condition -> Action 순으로 구현한다.
조건은 CHECK를 주로 사용한다.


Views, Virtual Tables in SQL
Defining table이라고 한다.
CREATE VIEW <view name> AS <query>로 만든다. 보통 Query가 빈번하게 발생하는 경우 View로 만들어서 관리한다.

생성된 view는 FROM에서 사용할 수 있다.
View는 항상 최신의 상태를 유지하고 있다.
DROP VIEW를 통해 지울 수 있다.
DROP command
Table, Domain, Constraint 등 이름을 지어준 구조를 지울 때 사용된다.
CASCADE, RESTRICT의 동작이 실행된다.
| CASCADE | RESTRICT |
| 값이 존재해도 지워버린다. 대신, 다른 참조에서 NULL로 바꾼다. |
데이터가 있으면 지우지 않는다. |
DROP SCHEMA COMPANY CASCADE 로 사용한다.
데이터에는 table, view, constraints 등이 포함된다.
Alter command
Attribute를 추가하거나 drop하는 경우 사용한다.
Attribute의 정의를 바꾸는 데 사용한다.
Table constraints를 바꾸는 데 사용한다.
ALTER TABLE COMPANY.EMPLOYEE ADD COLUMN Job VARCHAR(12);
*schema 이름을 명시할 수 있다.
ALTER TABLE COMPANY.EMPLOYEE DROP CONSTRAINT EMPSUPERFK CASCADE;
*CASCADE는 참조관계가 존재하면 NULL로 바꾸고 지워버린다.
Default value도 지우거나 만들 수 있다.
ALTER TABLE COMPANY.EMPLOYEE DROP COLUMN Mgr_ssn DROP DEFAULT;
ALTER TABLE COMPANY.EMPLOYEE DROP COLUMN Mgr_ssn SET DEFAULT '3331213';
'Study > Database' 카테고리의 다른 글
| 9. Introduction to Transaction (0) | 2023.05.02 |
|---|---|
| 8. Basics of Functional Dependencies and Normalization for Relational Databases (0) | 2023.05.02 |
| 6. Indexing Structures for Files and Physical Database Design (0) | 2023.05.02 |
| 5. Basic SQL (0) | 2023.05.02 |
| 4. The Relational Data Model & Relational Database Constraints (0) | 2023.05.02 |