
Functional Dependencies를 이용하여 DB를 정규화하는 방법을 배운다. 정규화의 목적은 NULL과 중복되는 값을 줄이는 데에 있다.
1. 좋은 DB를 설계하는 가이드라인
| GUIDELINE 1 |
| Relation에서 Tuple은 하나의 entity이거나 relationship instance여야 한다. 다른 entity의 attribute가 섞이면 안된다. |
| GUIDELINE 2 |
| 중복되는 정보가 있으면 저장공간의 낭비와 함께 INSERT, DELETE, UPDATE anomalies가 발생한다. INSERT - 부서를 추가하려면 사원이 필요한 데, 사원이 없는 경우 DELETE - 부서를 지웠더니 부서 안의 모든 사원 정보가 지워지는 경우 UPDATE - 하나만 업데이트했는데, 모든 정보 업데이트가 필요한 경우 따라서, anomaly가 발생하지 않도록 디자인한다. |
| GUIDELINE 3 |
| 최대한 NULL을 발생시키지 않도록 디자인한다. NULL이 발생하면, 따로 table을 만들어서 관리한다. |
| GUIDELINE 4 |
| 무손실 join이 일어나도록 디자인한다. 정규화 과정을 통해 분리하다 보면, 실재 존재하지 않는 데이터가 발생하기도 한다.(가짜 tuple) 가능하면 FD를 보장한다. |
2. Functional Dependencies
일종의 제약같은 느낌이다. 가령 학번이 정해지면 이름과 사는 곳을 알 수 있다. 이 경우 학번과 이름, 학번과 사는 곳 사이에 FD가 발생한다. 대부분의 경우, FD는 Interview 단계에서 파악한다. 가능한 모든 FD를 가정하고 안되는 경우를 지우며 파악한다.

"X -> Y"로 표기하며 X가 Y를 결정한다는 의미를 가진다. 역은 성립하지 않는다.
A->Y, B->Y는 FD가 가능하지만,
Y->A, Y->B는 FD가 아니다. (단, A,B는 같은 attribute)
| FD constrain 1 | FD constrain 2 |
| FD는 최소 단위로 이루어진다. | Key는 모든 attribute에 FD이다. |
3. Normalization
정규화 과정은 안좋은 relation의 attribute를 쪼개는 과정이다. Key와 FD를 이용해 분리한 결과를 Normal Form이라 한다. 정규화 정도에 따라서 2NF, 3NF, BCNF / 4NF / 5NF로 나뉘게 된다.
| 2NF, 3NF, BCNF | 4NF | 5NF |
| Key와 FD를 보고 진행한다 | Multi-valued dependencies, MVD를 보고 진행한다. | Key와 Join dependencies를 보고 진행한다. |
실제로 사용하는 정도는 3NF, BCNF이며 그 이상부터는 Denormalization을 진행한다. 이상의 것들의 결과는 너무 쪼개져 있어서 사용할 때마다 JOIN 연산이 필요하기 때문이다.
Superkey : 가능한 1개의 key
Candidate key : key가 여러개인 경우
Primary key : 선택된 key
Secondary key : 선택되지 못한 key
Prime attribute : Candidate key에 해당하는 attribute를 의미한다.
Nonprime attribute : Candidate key에 해당하지 않는 attribute를 의미한다.
3-1. 1NF
Atomic attribute만 사용하는 것이 목표이다.
Composite / Multivalued attribute를 허락하지 않는다.
Nested relation(attribute에 table이 들어가는 경우)을 허락하지 않는다.
3-2. 2NF
FD와 PK를 이용한다. FD 제약 1(최소단위 관계)을 지키는 것이 목표이다.
예시)
{SSN, PNUMBER} -> ENAME
--> {SSN} -> ENAME
정리하면, Nonprime attribute가 Prime attribute에 종속되게 만든다.
즉 Full FD와 최소단위 관계를 유지해야 한다.
3-3. 3NF
Transitive FD를 지우는 것이 목표이다.
예시)
"X -> Y -> Z"인데 "X -> Z"를 사용하는 경우,
--> "X -> Y" + "Y -> Z"로 분리하는 경우이다.
2NF를 만족하며, Nonprime attribute가 Transitive FD on PK가 아니라면 3NF를 만족한다.
정리하자면 다음의 내용을 확인하면 된다.
| 1NF | 2NF | 3NF |
| 모든 key가 atomic한지 확인한다. | Full FD를 유지하는 지 확인한다. | Transitive FD를 확인한다. |
3-4. BCNF
3NF으로도 확인하지 못하는 경우가 있다. 바로 "Nonprime attribute -> Prime attribute"인 경우이다. 이경우 BCNF를 사용하면 된다.
Boyce-Codd Normal Form, BCNF으로
X -> A에 대하여 X가 superkey인 경우에만 인정하는 것이다.
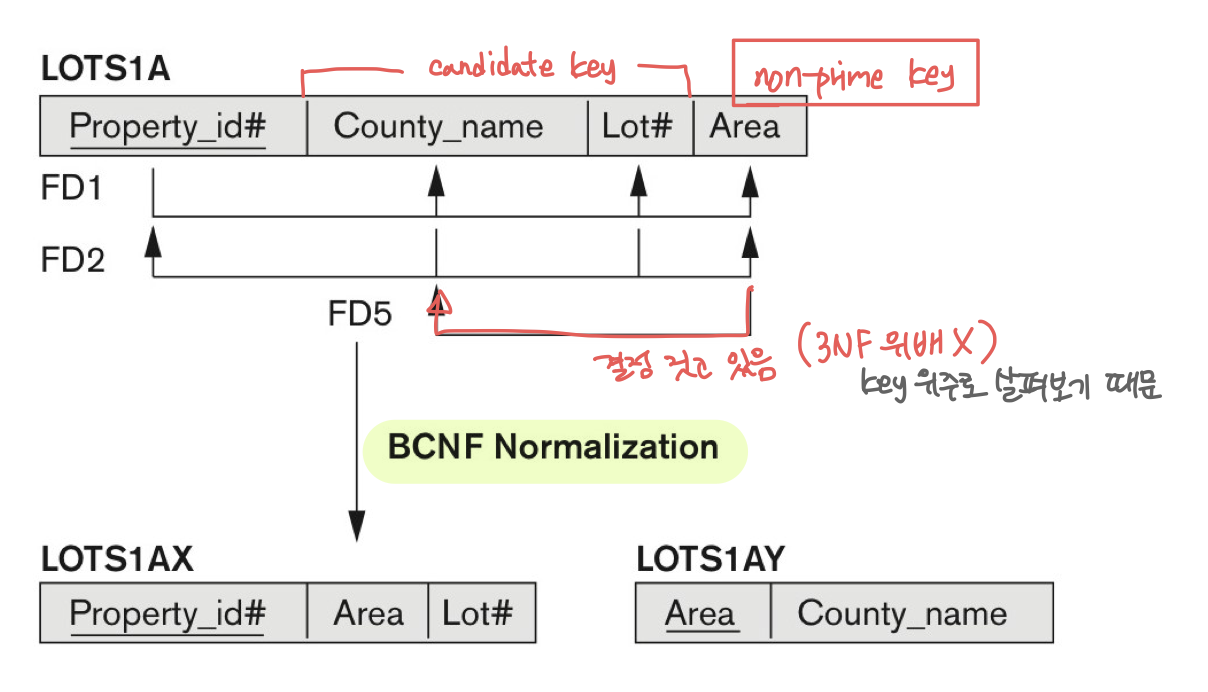
*3NF와 BCNF 차이
fd1: {student, course} -> instructor
fd2: instructor -> course
--> 3NF가 필요함 (transitive FD가 있으니까)
나눠질 수 있는 가능한 결과는 아래와 같음
D1: {student, instructor} and {student, course}
D2: {course, instructor} and {course, student}
D3: {instructor, course} and {instructor, student}
어떤 D를 사용할지 고려하는 방법은
- 두 개의 relation으로 분리
- "Relation 교집합 -> Relation 차집합" 이 가능하면 선택
풀이 과정은
- D1: student -> instructor, student -> course
- ...
전부 가능한 지 확인하고 가능한 FD가 있는 것을 사용한다.
3NF로는 해결할 수 없음, fd1을 만족할 수 없게 됨
BCNF에서는 해결 가능(FD를 꼭 맞춰야 하는 것은 아니기 때문)
-> D3로 나누면 된다.
3-5. 4NF
X ->> Y를 의미한다. 1:n의 관계이다.
Y가 X의 부분집합이거나 X U Y가 relation schema라면 trivial MVD라고 한다.
X가 superkey라면 4NF를 만족하게 된다.
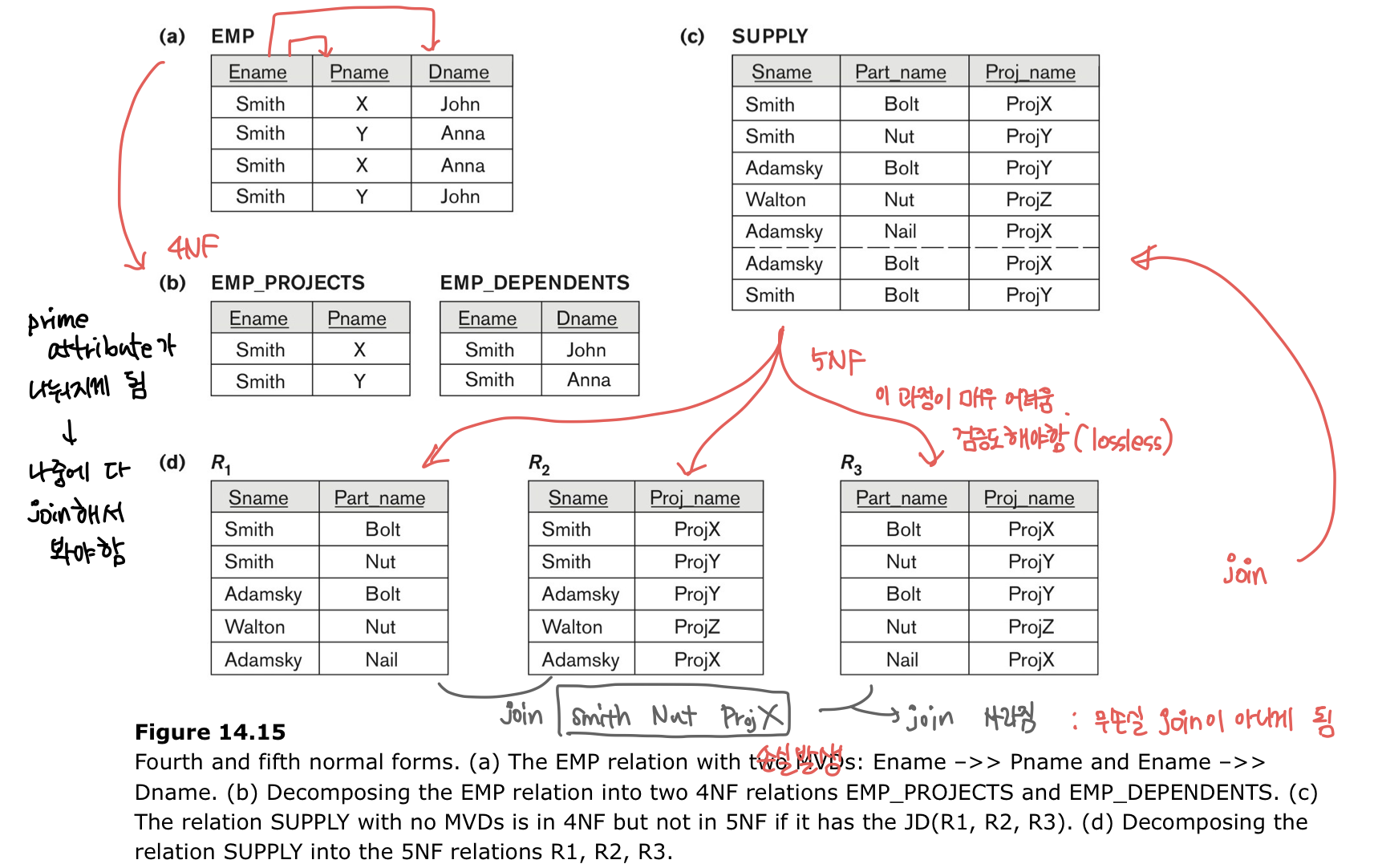
3-6. 5NF
가능한 최대한 작게 나누어서 테이블을 저장하는 방식이다.
'Study > Database' 카테고리의 다른 글
| 10. Concurrency Control (2) | 2023.05.02 |
|---|---|
| 9. Introduction to Transaction (0) | 2023.05.02 |
| 7. More SQL : Complex Queries, Triggers, Views, and Schema Modification (0) | 2023.05.02 |
| 6. Indexing Structures for Files and Physical Database Design (0) | 2023.05.02 |
| 5. Basic SQL (0) | 2023.05.02 |