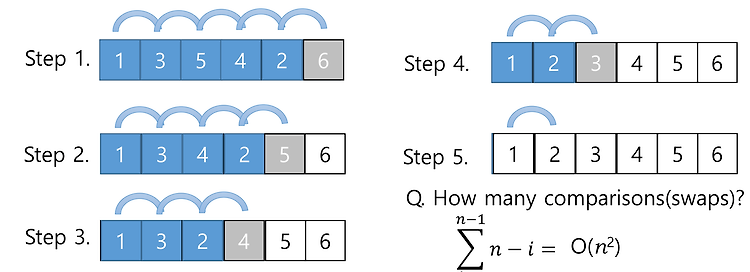
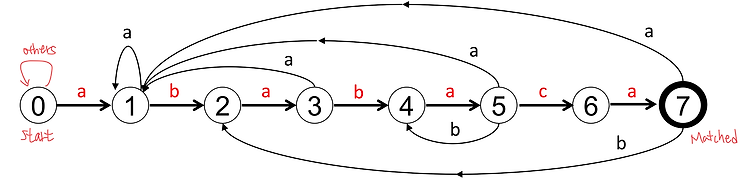
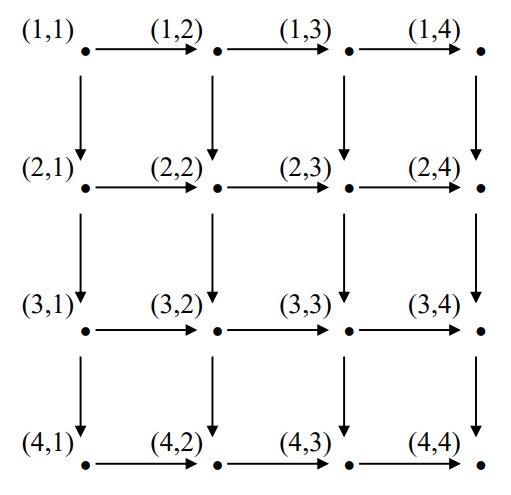
4. Probabilistic Analysis and Randomized Algorithm
알고리즘의 성능을 평가할 때, Time complexity를 분석하며, 이 값은 Input 데이터에 의해 바뀔 수 있다고 학습했습니다. Upper bound, Lower bound, Tight bound를 구하는 노력이 알고리즘의 Best case, Worst case, Average case와 관련이 있게 되는 이유이고요. 우리가 알고리즘을 평가할 때, Best case는 별로 관심이 없습니다. 실질적으로 사용하기 위해서는 Worst case와 Average case가 중요하기 때문입니다. Worst case에 대한 시간 복잡도는 비교적 쉽게 구할 수 있습니다. 알고리즘의 수도 코드를 보면서, 최악의 경우를 가정하고 instruction을 따라가면 되기 때문입니다. 반면 Average case는 가능한..
2023.06.08